Les Bases
- Base de Bash
- Processus
- Sudo
- Commande Basiques
- Cron
- Système de fichiers
- Swap
- Curl
- Sed
- AT
- Awk
- Find
- Tmux
- Copie de Fichiers avec scp
- Mise à jours automatique avec unattended-upgrades
- SSH - Ajout de la 2FA
- Connexion Clé SSH
- Comment changer l’ordre du boot avec GRUB
- How to Add a Directory to PATH in Linux
- Ajouter un MOTD dynamique
- Ajouter des couleurs à ses scripts shell
- Exécuter une action à la mise en veille / au réveil
- Antisèche
- Linux General Cheat Sheets
Base de Bash
Shell
Sous Linux, un shell est l’interpréteur de commandes qui fait office d’interface entre l'utilisateur et le système d’exploitation. Il s’agit d’interpréteurs, cela implique que chaque commande saisie par l’utilisateur et vérifiée puis exécutée. Nous avons déjà parlé des différents types de shell existants (csh, tcsh, sh, bash, ksh, dash, etc.). Nous travaillerons plus avec le bash (Bourne Again SHell).
Pour rappel, un shell possède deux principaux aspects :
- Un aspect environnement de travail
- Un aspect langage de programmation
L’environnement
L’environnement de travail d’un shell doit être agréable et puissant (rappel CLI GUI), bash permet entre autres choses de :
- Rappeler des commandes précédentes (historique)
- Modifier en ligne du texte de la commande courante (bi, emacs, nano)
- Gestion des travaux lancés en arrières-plan (jobs)
- Initialisation adéquate des variables de configuration (chaîne d’appel de l’interpréteur, chemins de recherche par défaut)
Pour illustrer ça, voyons que le shell permet d’exécuter une commande en mode interactif ou bien par l’intermédiaire de fichiers de commandes (scripts). En mode interactif, bash affiche à l’écran une chaîne d’appel (appelée prompt ou invite) qui se termine par défaut par le caractère # pour l’administrateur (root), et par le caractère $ pour les autres utilisateurs. Sous windows le prompt est souvent le nom du chemin où l’on se trouve, suivis de > , par exemple : “C:\Windows\System32>”
Un langage de programmation
Les shells ne sont pas uniquement des interpréteurs de commandes mais de véritables langages de programmation, un shell comme le bash intègre :
- les notions de variables
- les opérateurs arithmétiques
- les structures de contrôle
- les fonctions
- etc.
Par exemple :
$ mavariable=5 #=> affectation de la valeur 5 dans la variable qui a pour nom “mavariable”
$ echo $((mavariable +3)) #=> affiche la valeur de l’expression mavariable
8Avantages et inconvénients des shells
L’étude d’un shell comme le bash dispose de plusieurs avantages :
- langage interprété, il est facile de trouver les erreurs et de les traiter
- modification rapide sans besoin de recompiler
- langage orienté chaîne de caractères (pas de pointeurs), moins de risque d’avoir des erreurs d’adressage.
- prototypage rapide d’application, il est facile de composer des programmes avec les commandes existantes et l’utilisation des tubes et substitution dans l’environnement Unix
- langage “glu”: on peut connecter des composants écrits dans des langages différents. Ils doivent juste respecter certains standards :
- lire sur l’entrée standard
- accepter des arguments et options éventuels,
- écrire ses résultats sur la sortie standard
- écrire les messages d’erreurs sur la sortie dédiée au erreur.
Voyons maintenant certains inconvénients des shells :
- La syntaxe est “ésotérique” et d’accès difficile pour les débutants
- Suivant le contexte, l’ajout ou l’oubli d’un espace peut provoquer des erreurs de syntaxe ou de traitement
- Plusieurs syntaxes pour implanter la même fonctionnalité (principalement à cause de la compatibilité ascendante avec le Bourne Shell
- Le sens de certains caractères spéciaux, comme les parenthèses, change avec le contexte, elle peuvent définir :
- une liste de commandes
- une définition de fonction
- imposer un ordre d’évaluation
- une expression arithmétique
Si vous voulez connaître le shell qui tourne actuellement, utilisez la commande ps, et si vous voulez connaître la version du bash :bash -- version
Variables
Ils existent différents types de variables utilisables dans le shell. Elles sont identifiées par un nom (suite de lettres, chiffres, caractères espace
ou souligné ne commençant pas par un chiffre. la casse est gérée). On peut classer 3 groupes de variables :
- utilisateurs (ex: a, valeur)
- prédéfinies par le shell (ex; PS1, PATH, REPLY, IFS, HOME)
- prédéfinies pour les commandes unix (ex: TERM)
Pour affecter une variable, on peut utiliser l’opérateur = ou bien la commande interne read (pour demander une saisie utilisateur)
Les variables locales :
Elles ne sont disponibles que dans l’instance du shell dans lesquelles elles ont été créées. (Elles ne sont pas utilisées par les commandes dans ce shell). Par défaut une variable est créée en tant que variable locale, on utilise couramment des lettres minuscules pour nommer ses variables locales.
Exemple : mavariablelocale = 1
Les constantes :
Une constante est une variable en lecture seul d’une certaine manière, elle n’a pas pour but d’être modifié dans le programme (d’où son nom). Pour créer une constante, vous pouvez utiliser la commande declare -r.
Exemple: declare -r pi=3.14159
Les variables d’environnement :
Les variables d’environnement existent dans le shell pour lequel elles sont créées, mais aussi pour toutes les commandes qui sont utilisées dans ce shell. On utilise couramment des majuscules pour nommer ses variables d’environnement.
Exemple1 :
#Transformer une variable
ENVVAR=10 #Création d’une variable locale
export ENVVAR #Transforme la variable locale en variable d’environnementExemple 2:
# Créer une variable d’environnement
export ENVVAR2 = 11 # Première solution
declare -x ENVVAR3 = 12 # Deuxième solution
typeset -x ENVVAR4 = 13 # Troisième solutionCommandes utiles pour les variables :
- echo : Vous pouvez utiliser la commande echo si vous souhaitez connaître le contenu d’une variable.
Exemple : echo $PATH permettra d’afficher le contenu de la variable d’environnement PATH qui contient les chemins de fichier de
commande dans le shell.
$ set param1 param2
$ echo $1
param1
$ set --
$ echo $1
$ #on a perdu les valeursPour connaître le nombre de variables de position, il existe une variable spéciale $#
- shift : permet de décaler les variables de position (sans toucher au $0)
$ set a b c d e f g h i j # param 1 2 3 4 5 6 7 8 9
$ echo $1 $2 $#
a b 9
$ shift 2 # variable deviennent c d e f g h i j
$ echo $1 $2 $#
c d 7L’utilisation du shift sans argument équivaut à faire un shift 1
- unset : permet de supprimer une variable
$ set myvar=1
$ echo $myvar
1
$ unset myvar
$ echo $myvar
$Mon premier bash
#!/bin/bash
echo “Nom du programme : $0”
echo “Nombre d’arguments : $#”
echo “Source : $1”
echo “Destination $2”
cp $1 $2$ chmod u+x monpremierbash.sh
$
$ monpremierbash.sh /etc/passwd /root/copiepasswd
Nom du programme : ./monpremierbash.sh
Nb d’arguments : 2
Source : /etc/passwd
Destination : /root/copiepasswd
$$ set un deux trois quatre
$
$ echo $* # affiche tous les arguments
un deux trois quatre
$ echo $@ # affiche tous les arguments
un deux trois quatre
$ set un “deux trois” quatre # testons avec 3 paramètres et des guillemets
$ set “$*” # équivalent à set “un deux trois quatre”
$ echo $#
1
$ echo $1
un deux trois quatre
$ set un “deux trois” quatre # testons $@ avec 3 paramètres et des guillemets
$ set “$@” # équivalent à set “bonjour” “deux trois” “quatre”
$ echo $#
3
$ echo $2
deux troisSi dans un bash on souhaite supprimer les ambiguïtés d’interprétation des paramètres de position, on utilise le ${paramètre}, comme dans l’exemple suivant.
Exemple :
$ x=bon
$ x1=jour
$ echo $x1
jour
$ echo ${x}1
bon1
$ set un deux trois quatre cinq six sept huit neuf dix onze douze
$ echo $11
un1
$ echo ${11}
onzeIndirections
Bash offre la possibilité d’obtenir la valeur d’une variable v1 dont le nom est contenu “v1” dans une autre variable mavar. Il suffit pour cela d’utiliser la syntaxe de substitution : ${!mavar}.
Exemple :
$ var=v1
$ v1=un
$
$ echo ${!var}
un
$Ce mécanisme, appelé indirection,permet d’accéder de manière indirecte et par conséquent de façon plus souple, à la valeur d’un
deuxième objet. Voyons un autre exemple d’utilisation :
Exemple d’un fichier indir:
#!/bin/bash
agePierre=10
ageJean=20
read -p “Quel âge (Pierre ou Jean) voulez-vous connaître ? “ prenom
rep=age$prenom #construction du nom de la variable
echo ${!rep}
$ indir
Quel âge (Pierre ou Jean) voulez-vous connaître ? Pierre
10
$ indir
Quel âge (Pierre ou Jean) voulez-vous connaître ? Jean
20
$Ce mécanisme s’applique également aux deux autres types de paramètres : les paramètres de position et les paramètres spéciaux ($1, $2, , ...)
Résultats, Code de retour et opérateur sur les code de retour
Il ne faut pas confondre le résultat d’une commande et son code de retour : le résultat correspond à ce qui est écrit sur sa sortie standard; le code de retour indique uniquement si l’exécution de la commande s’est bien effectuée ou non. Parfois, on est intéressé uniquement par le code de retour d’une commande et non par les résultats qu’elle produit sur la sortie standard ou la sortie d’erreur.
Exemple :
$ grep toto pass > /dev/null 2>&1 #=> ou bien : grep toto pass &>/dev/null
$
$ echo $?
1 #=> on en déduit que la chaîne toto n’est pas présente dans passLes opérateurs && et || autorisent l’exécution conditionnelle d’une commande cmd suivant la valeur qu’a pris le code de retour de la dernière commande précédemment exécutée.
Exemple pour && :
$ grep toto pass > /dev/null 2>&1 #=> ou bien : grep toto pass &>/dev/null
$
$ echo $?
1 #=> on en déduit que la chaîne toto n’est pas présente dans passLa chaîne de caractères daemon est présente dans le fichier pass, le code de retour renvoyé par l’exécution de grep est 0; par conséquent, la commande echo est exécutée.
Exemple pour || :
$ ls pass tutu
ls : impossible d’accéder à tutu: Aucun fichier ou dossier de ce type pass
$ rm tutu || echo tutu non effacé
rm : impossible de supprimer tutu: Aucun fichier ou dossier de ce type
tutu non effacé
$Le fichier tutu n’existant pas, la commande rm tutu affiche un message d’erreur et produit un code de retour différent de 0; la commande interne echo est exécutée.
Exemple combiné || et || :
$ ls pass || ls tutu || echo fin aussi
pass
$Le code de retour ls pass est égal à 0 car pass existe, la commande ls tutu ne sera pas exécutée. D’autre part le code de retour de l’ensemble ls pass || ls tutu est le code de retour de la dernière commande exécutée, c’est-à-dire 0 (ls pass). donc echo fini aussi n’est pas exécutée.
Exemple combiné && et || :
$ ls pass || ls tutu || echo suite et && echo fin
pass
fin
$la commande ls pass a un code de retour égal à 0, donc la commande ls tutu ne sera pas exécutée; le code de retour de l’ensemble ls pass || ls tutu sera donc égal à 0. la commande echo suite et n’est pas exécutée donc le code de retour de l’ensemble reste 0 echo fin sera donc exécutée.
Boucles et structure de contrôle
case, structure de choix multiple
Syntaxe :
case mot in
[modele [ | modele] ...) suite de commandes ;; ] ...
esacLe shell va étudier la valeur de mot puis la comparer séquentiellement à chaque modèle. Quand un modèle correspond à mot, la suite de commandes associée est exécutée, terminant l’exécution de la commande interne case. Les mots case et esac sont des mots-clés; ils doivent être le premier mot d’une commande. suite de commandes doit se terminer par 2 caractères ; collés de manière à ce qu’il n’y ait pas d’ambiguïté avec l’enchaînement séquentiel de commande cmd1; cmd2; etc. Quand au modèle , il peut-être construit à l’aide de caractères et expressions génériques de bash (*, . , [], etc.). Dans ce contexte le symbole | signifiera OU. Pour indiquer le cas par défaut (si aucun des autres ne survient) on utilisera le modèle *. il doit être placé en dernier modèle. Le code de retour de la commande composée case est égal à 0, si aucun modèle n’a pu correspondre à la valeur de mot. Sinon, c’est celui de la dernière commande exécutée de suite de commandes.
Exemple 1: Programme shell oui affichant OUI si l’utilisateur a saisi le caractère o ou O
#!/bin/bash
read -p “Entrez votre réponse : “ rep
case $rep in
o|O ) echo OUI ;;
* ) echo Indefini
esacExemple 2 : Programme shell nombre prenant une chaîne de caractères en argument, et qui affiche cette chaîne si elle est constituée d’une suite de chiffres. ([:digit:] , [:upper:], [:lower:], [:alnum:]
#!/bin/bash
# on autorise l’utilisation des expressions générique
shopt -s extglob
case $1 in
+([[:digit:]]) ) echo ′′$1 est une suite de chiffres′′ ;;
esacExemple 3 : Si l’on souhaite ignorer la casse on peut modifier le flash de shopt
#!/bin/bash
read -p “Entrez un mot : “ mot
shopt -s nocasematch
case $mot in
oui ) echo ′′Vous avez écrit oui” ;;
* ) echo “$mot n’est pas le mot oui” ;;
esacWhile
La commande interne while correspond à l’itération ‘faire - tant que’ présente dans de nombreux langage de programmation.
Syntaxe :
while suite_cmd1
do
suite_cmd2
doneLa suite de commandes suite_cmd1 est exécutée, si son code de retour est égal à 0, alors la suite de commande suite_cmd2 est exécutée, puis suite_cmd1 est re-exécutée. Si son code de retour est différent de 0, la suite se termine. L’originalité de cette méthode est que le test ne porte pas sur une condition booléenne, mais sur le code de retour issu de l’exécution d’une suite de commandes. Une commande while, comme toutes commandes internes, peut être écrite directement sur la ligne de commande.
Exemple :
$ while who | grep root> /dev/null
> do
> echo “Utilisateur root est connecté”
> sleep 5
> done
Utilisateur root est connecté
Utilisateur root est connecté
Utilisateur root est connecté
^C
$Commande interne while est :
La commande interne : associée à une itération while compose rapidement un serveur (démon) rudimentaire.
Exemple :
$ while : #=> Boucle infinie
> do
> who | cut -d’ ‘-f1 > fic #=> Traitement à effectuer
> sleep 300 #=> Temporiser
> done &
[1] 1123 #=> pour arrêter l’exécution kill -15 1123
$On peut parfois utilisée la commande while pour lire un fichier texte. La lecture se fait alors ligne par ligne. Pour cela, il suffit de :
- placer la commande read dans suite_cmd1
- de placer les commandes de traitement de la ligne courante dans suite_cmd2
- de rediriger l’entrée standard de la commande while avec le fichier lire
Syntaxe :
while read [var1 ...]
do
Commandes de traitements
done < fichier à lireExemple :
#!/bin/bash
who > tmp
while read nom divers
do
echo $nom
done < tmp
rm tmpNotez que l’utilisation du while pour lire un fichier n’est pas très performante. On préférera en général utiliser une suite de filtre pour obtenir les résultats voulus (cut, awk, ...)
Modificateur de chaîne
Échappement
Différents caractères particuliers servent en shell pour effectuer ses propres traitements ($ pour la substitution, > pour la redirection, * en joker). Pour utiliser ces caractères particuliers en tant que simple caractère, il faut les échapper en les précédant du caractère \
Exemple :
$ ls
tata toto
$ echo *
tata toto
$ echo \*
*
$ echo \\
\
$Autre particularité, le caractère \ peut aussi échapper les retours à la ligne. On peut donc aller à la ligne sans exécuter la commande.
Comme nous l’avons déjà vu, les caractères “ et ‘ permettre une protection partielle, ou total (‘) d’une chaîne de caractères.
Exemple :
$ echo “< * $PWD ‘ >”
< * /root ‘ >
$
$ echo “\”$PS2\””
“> “
$ echo ‘< * $PWD “ >’
< * $PWD “ >’
$ echo c’est lundi
>
> ‘
cest lundi
$ echo c\’est lundi
c’est lundi
$ echo “c’est lundi”
c’est lundiChaîne de caractères longueur
Syntaxe : ${#paramètre}
Cette syntaxe permet d’obtenir la longueur d’une chaîne de caractères.
Exemple :
$ echo $PWD
/root
$ echo ${#PWD}
5
$ set “Bonjour à tous”
$ echo ${#1}
14
$ ls > /dev/null
$
$ echo ${#?}
1 #=> la longueur du code de retour (0) est de 1 caractèreChaîne de caractères modificateur
On peut modifier les chaîne de caractères directement :
Syntaxe : ${paramètre#modèle} pour supprimer la plus courte sous-chaîne à gauche
Exemple :
$ echo $PWD
/home/christophe
$ echo ${PWD#*/}
home/christophe #=> le premier caractère / a été supprimé
$
$ set “25b75b”
$
$ echo ${1#*b}
75b #=> Suppression de la sous-chaîne 25bSyntaxe: ${paramètre##modèle} pour supprimer la plus longue sous-chaîne à gauche
Exemple :
$ echo $PWD
/home/christophe
$ echo ${PWD##*/}
christophe #=> suppression jusqu’au dernier caractère /
$
$ set “25b75b”
$
$ echo ${1##*b}
bPour la suppression par la droite, c’est la même chose en utilise le caractère % comme contrôle
Syntaxe :${paramètre%modèle} pour supprimer la plus courte sous-chaîne à droite${paramètre%%modèle} pour supprimer la plus longue sous-chaîne à droite
On peut extraire une sous-chaîne également :
Syntaxe:${paramètre:ind} : extrait la valeur de paramètre de la sous-chaîne débutant à l’indice ind.${paramètre:ind:nb} : extrait nb caractères à partir de l’indice ind
Exemple :
$ lettres=”abcdefghijklmnopqrstuvwxyz”
$
$ echo {$lettre:20}
uvwxyz
$ echo {$lettre:3:4}
defg
$Remplacement dans une sous-chaîne
Syntaxe:${paramètre/mod/ch}
bash recherchera dans paramètre la plus longue sous-chaîne satisfaisant le modèle mod puis remplacera cette sous-chaîne par
la chaîne ch. Seule la première sous-chaîne trouvée sera remplacée. mod peut être des caractères ou expressions génériques.${paramètre//mod/ch} :
Pour replacer toutes les occurrences et pas seulement la première${paramètre/mod/} :${paramètre//mod/} :
Supprime au lieu de remplacer
Exemple :
$ v=totito
$ echo {$v/to/lo}
lotito
$ echo {$v//to/lo}
lotiloStructure de contrôle for et if
Itération et for
Syntaxe 1:
for var
do
suite_de_commandes
done
Syntaxe 2:
for var in liste_mots
do
suite_de_commandes
doneDans la première forme, la variable var prend successivement la valeur de chaque paramètre de position initialisé
Exemple :
$ cat for_args.sh
#!/bin/bash
for i
do
echo $i
echo “next ...”
done
$ ./for_args.sh first second third
first
next ...
second
next ...
third
next ...Exemple 2:
$ cat for_set.sh
#!/bin/bash
set $(date)
for i
do
echo $i
done
$ ./for_set.sh
samedi
29
Juin
2019,
12:09:21
(UTC+0200)
$La deuxième syntaxe permet à var de prendre successivement la valeur de chaque mot de liste_mots.
Exemple :
$ cat for_liste.sh
#!/bin/bash
for a in toto tata
do
echo $a
doneSi liste_mots contient des substitutions, elles sont préalablement traitées par bash
Exemple 2:
$ cat affiche_ls.sh
#!/bin/bash
for i in /tmp ${pwd}
do
echo “ --- $i ---”
ls $i
done
$ ./affiche_ls.sh
--- /tmp ---
toto tutu
--- /home/christophe
for_liste.sh affiche_ls.sh alpha tmpIf et le choix
La commande interne if implante le choix alternatif
Syntaxe :
if suite_commande1
then
suite_commande2
[elif suite_de_commandes; then suite_de_commande] ...
[else suite_de_commandes]
fiLe principe de fonctionnement est le même que pour le for, on test la valeur de retour d’une commande plutôt qu’une valeur booléenne simple. Donc dans notre exemple, suite_commande2 est exécuté, si suite_commande1 renvoi 0 (pas d’erreur). Sinon c’est elif ou bien else qui sera exécuté.
Exemple :
$ cat rm1.sh
#!/bin/bash
if rm “$1” 2> /dev/null
then echo $1 a été supprimé
else echo $1 n\’a pas été supprimé
fi
$ >toto
$ rm1 toto
toto a été supprimé
$
$ rm1 toto
toto n’a pas été supprimé
$Lorsque rm1 toto est lancé, si le fichier toto est effaçable, il le sera, et la commande rm renvoi 0.
Notez qu’il est possible d’imbriquer les if ensembles
Exemple :
if...
then....
if...
then ...
fi
else ...
fiTests
Dans les bash, vous retrouverez souvent une notation de commande interne [[ souvent utilisé avec le if. Elle permet l’évaluation de d’expressions conditionnelles portant sur des objets aussi différents que les permissions sur une entrée, la valeur d’une chaîne de caractères ou encore l’état d’une option de la commande interne set.
Syntaxe: [[ expr_conditionelle ]]
Les deux caractères crochets doivent être collés et un caractère séparateur doit être présent de part et d’autre de expr_conditionelle. Les mots [[ et ]] sont des mots-clés. On a vu que le if fonctionne selon la valeur de retour d’une commande, et pas d’un booléen, cette syntaxe permet “d'exécuter un test” qui renverra 1 si le test est vrai, 0 sinon. Si l’expression contient des erreurs syntaxique une autre valeur sera retournée. La commande interne [[ offre de nombreuses expressions conditionnelles, c’est pourquoi seules les principales formes de exp_conditionnelle seront présentées, regroupées par catégories.
Permission
-r entrée vraie si entrée existe et est accessible en lecture par le processus courant
-w entrée vraie si entrée existe et est accessible en écriture par le processus courant
-x entrée vraie si entrée existe et est accessible en exécutable par le processus courant ou si le répertoire entrée existe et
le processus courant possède la permission de passage
Exemple :
$ echo coucou > toto
$ chmod 200 toto
$ ls -l toto
--w- --- --- 1 christophe christophe 29 juin 1 14:04 toto
$
$ if [[ -r toto ]]
> then cat toto
> fi
$ => rien ne ce passe
$ echo $?
0 => code de retour de la commande interne if
$
MAIS
$ [[ -r toto ]]
$ echo $?
1 => code de retour de la commande interne [[
$Type d’une entrée
-f entrée vraie si entrée existe et est un fichier ordinaire
-d entrée vraie si entrée existe et est un répertoire
Exemple :
$ cat afficher.sh
#!/bin/bash
if [[ -f “$1” ]]
then
echo “$1” : fichier ordinaire
cat “$1”
elif [[ -d “$1” ]]
then
echo “$1” : répertoire
ls “$1”
else
echo “$1” : type non traité
fi
$ ./afficher
. : répertoire
afficher.sh test.sh toto alpha rm1.sh
$Renseignement divers sur une entrée
-a entrée vraie si entrée existe
-s entrée vraie si entrée existe et sa taille est différente de 0 (un répertoire vide > 0)
entrée 1 -nt entrée 2 vraie si entrée 1 existe et sa date de modification est plus récente que celle de entrée2
entrée1 -ot entrée 2 vraie si entrée1 existe et sa date de modification est plus ancienne que celle de entrée2
Exemple :
$ > err
$
$ ls -l err
-rw-rw-r-- 1 christophe christophe 0 juin 29 14:30 err
$ if [[ -a err ]]
> then echo err existe
> fi
err existe
$ if [[ -s err ]]
> then echo err n’est pas vide
> else err est vide
> fi
err est vide
$Longueur d’une chaîne de caractère
-Z ch vraie si la longueur de ch est égale à 0
ch ou (-n ch) vraie si la longueur de ch est différente de 0
ch1 < ch2 vraie si ch1 précède ch2
ch1 > ch2 vraie si ch1 suit ch2
ch == mod vraie si la chaîne ch correspond au modèle mod
ch != mod vraie si la chaîne ch ne correspond pas au modèle mod
-o opt vraie si l’option interne opt est sur on
Important : il existe un opérateur =~ qui permet de mettre en correspondance une chaîne de caractères ch avec une expression
régulière.
Exemple :
$a=01/01/2010
$[[ $a =~ [0-9]{2}\/[0-9]{2}\/[0-9]{2,4} ]]
$ echo $?
0
$ a=45/54/1
$[[ $a =~ [0-9]{2}\/[0-9]{2}\/[0-9]{2,4} ]]
$ echo $?
1Expressions conditionnelles
( cond ) vraie si cond est vraie
! cond vraie si cond est fausse
cond1 && cond 2 vraie si cond1 et 2 sont vraie, l’évaluation s’arrête si cond1 est fausse
cond1 || cond2 vraie si cond1 ou 2 sont vraie.
Exemple :
$ ls -l /etc/at.deny
-rw-r----- 1 root daemon 144 oct. 25 2018 /etc/at.deny
$
$ if [[ ! ( -w /etc/at.deny || -r /etc/at.deny ) ]]
> then
> echo OUI
> else
> echo NON
> fi
OUIProcessus
Une commande sous linux crée un processus en mémoire, ce processus est sous la responsabilité du kernel. Tous les traitements effectués par une commande sont en fait traitées par le processus qui est créé lors de l'exécution de cette commande.
Un processus est exécuté (en général) par un utilisateur, il disposera donc des mêmes droits que l’utilisateur qui est responsable de son exécution. Et en général, un utilisateur ne pourra pas agir sur un processus lancé par un autre utilisateur, exception faite de root, évidemment.
La commande qui permet de lister les processus est PS :
PID : Numéro du processus (unique)
TTY : Nom du terminal dans lequel se trouve le processus
TIME : Le temps processeur utilisé par le processus
CMD : La commande qui a créé le processus
On peut déduire de cet exemple, qu’une même commande peut créer plusieurs processus.
Avec la commande ps x on peut voir dans quel état sont les processus
S: en sommeil
D : Sommeil irréversible
R : En cours d’exécution
T : Stoppé
Z : Zombie (processus terminé, mais pas encore totalement libéré)
Pour l’instant, on ne visualise que les processus de l’utilisateur, pour obtenir la liste complète, on va utiliser plutôt la commande :
ps -ef (-e tous les processus, et -f pour full détails)
Processus Foreground
Lorsque vous exécutez une commande comme ps -ef | less, le processus créé est foreground ou d’avant-plan. C’est-à-dire que le shell est bloqué durant l'exécution de la commande. L’utilisateur n’a donc plus la possibilité de faire autre chose. C’est pratique si le traitement est court, mais pas bon du tout si le traitement est long et coûteux en ressource.
Lorsqu'un processus a besoin de lancer un autre processus pour ses traitements, le premier processus est appelé processus parent et le ou les processus créés par le parent sont appelés processus enfant.
Lorsqu’un parent lancé en foreground crée un enfant, le processus enfant bloquera le parent jusqu’à la fin de ses traitements, puis à sa mort, le parent reprendra le relais.
Par exemple, le bash est un processus. Quand on lance une commande dans le bash, le processus parent bash est bloqué jusqu’à la fin des traitements de son processus enfant (par exemple le ls)
Si vous voulez éviter de bloquer le shell (ou le parent). Il est possible de lancer une commande en tâche de fond, dans ce cas, l’enfant rendra immédiatement les droits de continuer les opérations au parent, tout en continuant de faire ses traitements.
Pour se faire, on utilisera le caractère &,
Déplacer un processus
Si l’on fait un script, dont une commande demande à dormir 10.000 secondes, mais malheureusement, j’ai oublié de demander à la commande du script de se lancer en tâche de fond
- Le ctrl+z permet d'interrompre le processus (suspend)
- on fait la commande bg, qui passe le processus en tâche de fond
- on le remet en foreground avec la commande fg
- le ctrl+c permet de lancer une interruption logiciel qui envoi un SIGTERM au processus en foreground
Si vous voulez connaître la liste des jobs en cours de traitement, vous pouvez utiliser la commande jobs
Signaux
Un signal est un message envoyé à un processus pour altérer son état (par exemple stop, start, pause)
Certains signaux peuvent s’envoyer avec un raccourcis clavier (ctrl+z stoppe un processus)
Pour consulter la liste des signaux, kill -l
Donc la commande kill permet d’envoyer un signal à un processus de plusieurs façons :
- Kill -2 → envoi le signal 2 (SIGINT) à un processus
- Kill -SIGINT → envoi le signal SIGINT à un processus
Le SIGINT est l’équivalent du CTRL+Z (stoppe le processus mais ne le détruit pas)
Pour tuer (détruire) un processus, on utilisera plutôt le SIGTERM (15)
Killall - tuer un processus par user
La commande killall -u permet de demander à tuer tous les processus appartenant à un utilisateur.
killall -u root
Supprimera tous les processus lancés par le compte root.
Conserver un processus en quittant
Quand un utilisateur se déconnecte de sa session, tous les processus rattachés à l’utilisateur reçoivent un SIGHUP (1) qui va finalement tuer
tous les processus rattachés.
Si l’opération de sauvegarde est très longue et que l’administrateur doit se déconnecter, sa sauvegarde s’arrêtera par exemple.
Pour éviter ce phénomène, on utilisera la commande nohup
Priorité d’un processus
Un processus a besoin de temps processeur pour faire ses calculs. Certains d’entre eux ont droits à plus de CPU que d’autres, ceci se règle
avec un mécanisme de priorité. Les processus lancés par le système auront en général plus de priorité que les autres.
C’est le kernel qui s’occupe d’ajuster dynamiquement la priorité et essaie de fournir les bonnes priorités selon les besoins.
L’utilisateur pourra influencer dans une certaines mesure cette priorité en faisant varier une valeur de “gentillesse” niceness !
niceness -20 => Donne la priorité la plus haute possible
niceness 0 => valeur par défaut
niceness 19 => priorité la plus basse
Un utilisateur standard aura le droit de régler l’indice entre 19 et 0. Seul le root peut faire des réglages entre -1 et -20.
Pour affecter un indice de gentillesse, on utilise la commande nice avec l’option -n (régler la gentillesse) et une valeur.
Sudo
Sudo (Parfois considéré comme l'abréviation de Super-user do) est un programme dont l'objectif de permettre à l'administrateur du système d'autoriser certains utilisateurs à exécuter des commandes en tant que superutilisateur (ou qu'un autre utilisateur). La philosophie qui sous-tend cela est de donner aussi peu que possible de droits, mais de permettre quand même aux utilisateurs de faire leur travail. Sudo est aussi un moyen efficace d'enregistrer qui a exécuté quelle commande et quand.
Notes pour les nouveaux utilisateurs de Debian
Certains nouveaux utilisateurs de Debian, venant généralement de Ubuntu, sont choqués par les problèmes du type : « sudo ne fonctionne pas dans Debian ». Cette situation n'arrive cependant que si vous avez configuré un mot de passe superutilisateur (root) durant l'installation de Debian.
Si vous aimez sudo que vous voulez l'installer (même si vous l'avez sauté durant l'installation de votre Debian), vous pouvez, devenir superutilisateur avec la commande su, l'installer, et vous ajouter votre propre nom d'utilisateur dans le groupe sudo et faire une déconnexion puis une reconnexion complète.
Exemple :
-
su - #Password: (entrez ici le mot de passe superutilisateur que vous avez défini dans l'installation de votre Debian et appuyez sur la touche #Entrée) apt install sudo sudo adduser USER sudo
Puis veuillez effectuer une complète déconnexion et reconnexion.
Pourquoi pas sudo ?
Notez que, historiquement, tous les systèmes de type Unix fonctionnaient parfaitement même avant que « sudo » ne doit inventé. De plus, avoir un système sans sudo pourrait apporter encore plus de sécurité car le paquet sudo pourrait être affecté par des bogues de sécurité, comme toute partie additionnel de votre système.
Nombre d'utilisateur de Debian n'installent pas sudo. Ils ouvrent à la place un terminal en tant que supertulisateur (par exemple avec la commande su - à partir d'un utilisateur normal). Ainsi, vous n'avez pas placer « sudo » devant n'importe quelle commande.
Pourquoi sudo ?
Utiliser sudo pourrait être un plus familier pour les nouveaux utilisateur et est meilleur (plus sûr) que d'ouvrir une session en tant que superutilisateur pour un certain nombre de raisons dont :
-
Personne n'a à connaitre le mot de passe du superutilisateur (
sudodemande le mot de passe de l'utilisateur courant). Des droits supplémentaires peuvent être accordés temporairement à des utilisateurs puis retirés sans qu'il soit besoin de changer de mot de passe. -
Il est facile de n'exécuter que les commandes qui nécessitent des droits spéciaux avec
sudoet le reste du temps, on travaille en tant qu'utilisateur non-privilégié, ce qui réduit les dommages que l'on peut commettre par erreur. - Contrôler et enregistrer : quand une commande sudo est exécutée, le nom de l'utilisateur et la commande sont enregistrés.
Pour toutes les raisons ci-dessus, la possibilité de basculer en superutilisateur en utilisant sudo -i (ou sudo su) est habituellement désapprouvée parce que cela annule la plupart les avantages cités ci-dessus.
Commande Basiques
Passer en super utilisateur.
sudo -sAfficher le répertoire de travail courant.
pwdSe déplacer dans un répertoire.
cd (Dossier)Aller à la racine du disque dur.
cd /Se déplacer dans le répertoire parent.
cd ..Visualiser le contenu du répertoire.
lsPermet de créer un répertoire.
mkdir (Dossier)Supprimer un répertoire.
rmdir (Dossier)Permet de supprimer un dossier avec des fichiers dedans.
rm -rf dossierAffiche l’aide d’une commande.
man (Logiciel)Permet d’afficher un fichier texte (page par page ou en entier).
more (Fichier)cat (Fichier)Permet de modifier un fichier texte.
nano (Fichier)vi (Fichier)Permet de copier un fichier ou un dossier.
cp /etc/fichier (source) /tmp/fichier (destination)Permet de déplacer un fichier ou un dossier ou de le renommer
mv /etc/fichier (source) /tmp/fichier (destination)mv fichier fichierrenommerCréer un fichier
touch fichierPermet de supprimer un fichier.
rm fichierCron
Le démon crond est le processus qui permet d’exécuter des tâches planifiées automatiquement à des instants précis prévus à l’avance (date,
heure, minute) et en gérant une chronicité.
Si par exemple je veux qu’une machine PC-560 s’éteigne tous les jours à 20h51, je peux le faire avec cron. Pour cela, il me faut une entrée
dans la crontab de la machine qui indiquera la commande à exécuter pour éteindre la machine.
Normalement, cron est installé par défaut sur les systèmes, sinon vous pouvez l’installer comme d’habitude.
Toutes les configurations exécutées par cron vont se retrouver dans la table de cron (crontab). Seul la syntaxe particulière est complexe à
utiliser.
Utilisation de la crontab
Pour paramétrer une tâche planifiée, il faut écrire une entrée dans la crontab. Cette entrée spécifie la (ou les) date d’exécution de cette tâche,
ainsi que la tâche à exécuter et d’autres paramètres si nécessaire.
Pour chaque utilisateur du système, on peut éditer un fichier de crontab, relatif aux tâches planifiées de ce dernier. Ces fichiers se trouvent en
général dans “/var/spool/cron/crontabs/” ou un équivalent et portent le nom de l’utilisateur en question.
L’édition du fichier ne se fait pas en direct dans le spool, on utilisera une commande dédié pour ça :
- crontab -e pour éditer le fichier de crontab de l’utilisateur courant
- crontab -e -u root pour éditer la crontab d’un utilisateur spécifique (root)
- crontab -l pour afficher la crontab de l’utilisateur courant.
- crontab -r qui va effacer la crontab de l’utilisateur
En général au premier lancement, le système vous demandera quel moteur de texte vous souhaitez utiliser (nano, vi, ...) en fonction de ceux
installé. En sortie du fichier, le système vérifiera que la syntaxe de vos entrées est correct.
Il est important de noter, que le système dispose, en plus du crontab utilisateurs, de ses propres fichiers et tâches planifiées dans les
répertoires “/etc/cron.*” l’étoile représente les différents dossiers utilisés (qui sont référencés dans /etc/crontab) :
- cron.hourly toutes les heures
- cron.daily tous les jours
- cron.weekly toutes les semaines
- cron.monthly tous les mois
- cron.d contient des fichiers au format crontab pour des utilisations plus spécifiques.
Syntaxe de cron
Chaque entrée dans la crontab correspond à une tâche à exécuter. Et chaque entrée de la crontab est une ligne dans un des fichiers cités plus
haut. Si nous regardons une ligne en détail :
Exemple :51 19 * * 0 root /usr/local/bin/backupbackup
Cette ligne signifie de lancer le programme /usr/local/bin/backupbackup tous les dimanches à 19h51.
La syntaxe générale d’écrit sous cette forme :
mm hh jj MMM JDS commande
mm : Codé sur 2 chiffres représente les minutes de 0 à 59, ou * pour décrire toutes les minutes
hh : Codé sur 2 chiffres représente les heures de 0 à 23, ou * pour décrire toutes les heures
jj : Codé sur 2 chiffres représente la date du jour de 1 à 31, * pour décrire tous les jours
MMM : Codé sur 2 chiffres ou 3 lettres représente le mois de 1 à 12 ou de jan à dec, * pour décrire tous les mois
JDS : représente le jour de la semaine codé par 1 chiffre ou 3 lettres (de 0 à 7 ou de sun à sun, le 0 et le 7 représente sunday)
commande : la commande qui sera exécutée.
On peut trouver des caractères spéciaux dans les champs prévus pour :
- * : signifie tout ou chaque unité de temps.
- , : permet de décrire une liste. Exemple 3,5,17
- - : permet de décrire un intervalle. Exemple de 1 à 10 se note 1-10
- */ : permet de décrire un intervalle avec des pas différents de 1. Par exemple : */10 signifie 0,10,20,30, ...
- @reboot : permet de lancer la commande au démarrage de la machine
- @yearly : tous les ans
- @daily : tous les jours
Vous pouvez également vous renseigner sur anacron, pour que les tâches soient exécutées même si la machine est éteinte (ou au moins au
redémarrage de celle-ci).
Système de fichiers
Un système de fichiers est une façon d’organiser et de stocker une arborescence sur un support (disque, cd, ...). Chaque OS a sa propre organisation.
Linux possède son système appelé ext2 mais peut en gérer d’autres. La liste se trouve en général dans /proc/filesystems. L’utilisateur peut donc accéder sous Linux à d’autres systèmes de fichiers (DOS, Vfat, NTFS, ...) provenant d’un périphérique ou importé par le réseau.
Tout est fichier
Comme nous l’avons vu précédemment, dans le système linux, tout est considéré comme un fichier :
- Les fichiers
- Les dossiers
- Un disque dur
- La mémoire
- Un port USB aussi .
Mais parmi ces fichiers, tous n’ont pas la même catégorie. On peut en effet retrouver :
- fichiers normaux (texte, exécutables, ...); symbole “-”
- fichiers répertoires, ce sont des fichiers conteneurs qui contiennent des références à d’autres fichiers. Véritable charpente de
l’arborescence.; symbole “d”
- fichiers spéciaux, ils sont situés dans /dev, ce sont les points d’accès préparés par le système aux périphériques. Le montage va
réaliser une correspondance de ces fichiers spéciaux vers leur répertoire “point de montage”. Par exemple, le fichier /dev/hda permet l’accès et le chargement du 1er disque IDE.
- Accès caractère par caractère; symbole “c”
- Dispositif de communication ; symbole “p”
- Accès par bloc ; symbole “b”
- fichier lien symboliques, ce sont des fichiers qui ne contiennent qu’une référence (un pointeur) à un autre fichier. Cela permet d’utiliser un même fichier sous plusieurs noms sans avoir à le dupliquer sur le disque. ; symbole “l”
Le processus de montage que l’on évoque pour les fichiers spéciaux, avec sa commande mount est le moyen de faire correspondre les parties de l’arborescence et les partitions physiques de périphérique. Il permet de plus d’affecter tout système extérieur (cd, zip, réseau) à un répertoire créé pour cela dans l’arborescence. Il suffira ensuite de se déplacer à ce répertoire, appelé point de montage, qui est en fait un répertoire “d’accrochage”, pour accéder à ses fichiers (bien sûr, conformément aux permissions que possède l’utilisateur).
FHS (Filesystem hierarchy standard)
C’est la standardisation des noms et des emplacements des dossiers, et de leurs contenus.
Voici la structure qui est recommandée d’après les spécifications
SI l’on détaille :
- /bin : Les fichiers binaires les plus importants
- /boot : le Kernel et le bootloader
- /dev : les périphériques
- /etc : les fichiers de configurations spécifiques à l’ordinateur
- /home : Emplacement contenant les profils dossiers utilisateur
- /mnt : Emplacement d’accès aux systèmes de fichiers montés dans l’OS
- /lib : Bibliothèques de fonctions utilisées par les commandes /bin et /sbin
- /proc : Le kernel place ici l’état en temps réel du fonctionnement du système et des processus
- /root : Dossier du profil “root”
- /sbin : Contient des exécutables
- /tmp : à utiliser pour la création de fichiers temporaires
- /usr : Applications installées par les utilisateurs (et souvent les données qui vont avec) souvent un des plus lourds!
- /var/log : Fichiers logs
- /var/spool : File d’attente d’impression
- /var/tmp : Fichiers temporaires
Gob et Jokers
Le file globing, est l’opération qui transforme un caractère joker en une liste de chemins, et de fichiers correspondants qui formeront le résultat.
Le file globing est l’ancêtre des expressions régulières. Sous Bash, les jokers possibles sont :
- Le caractère *
- Le caractère ?
- Les caractères []
Le caractère * est utilisé pour obtenir la liste de tout le contenu
Ex : ls => ls *
Il est possible de préciser plus de caractéristiques :
ls D* => Tous les fichiers commençant par un D
ls d*v* => Tous les fichiers commençant par un d minuscule mais contenant aussi la lettre v
Le caractère ?, est utilisé pour préciser que le résultat doit contenir un seul ou plusieurs caractères (un par joker ?)
Exemple :
ls ? => liste tout ce qui ne contient qu’un seul caractère
ls ?? => liste tous les fichiers qui n’ont que 2 caractères
ls w?? => liste tous les fichiers qui ont 3 caractères et commençant par w
ls w??* => liste tous les fichiers qui commencent par w et contiennent au moins 3 caractères.
Le joker [], est utilisé pour spécifier une plage de caractères admissibles.
ls [a-f]?? => liste tous les fichiers dont la première lettre commence par a,b,c,d,e ou f et faisant 3 caractères.
ls [w]* => liste tous les fichiers commençant par w
ls [*] => ici l’étoile est son propre caractère, liste tous les fichiers commençant par *
ls *[0-9][0-9]* => liste tous les fichiers contenant 2 chiffres
ls [!a-y]* => ne liste que les fichiers commençant par autre chose que les lettres a à y. le ! inverse le résultat
ls *[^3-9] => liste tous les fichiers excluant ceux contenant les chiffres 3 à 9
Droit d’accès et permissions
Droits
Un fichier est caractérisé par un certain nombre de droits d’utilisation. Lorsque que l’on fait un ls -l, on remarque les éléments suivants :
le premiers bloc est définie comme suit :
_ Type de fichier (d, -, p, l, ...)
_ _ _ Droits du propriétaire du fichier (owner), dans l’ordre (lecture, écriture, exécution)
_ _ _ Droits du groupe auquel appartient le fichier (group), dans l’ordre (lecture, écriture, exécution)
_ _ _ Droits d’un utilisateur quelconque (user), dans l’ordre (lecture, écriture, exécution)
Pour rappel :
| Permission | Effet sur le fichier | Effet sur le dossier |
| r (read) | Autorise la lecture ou la copie du fichier et son contenu |
Sans droit d'exécution : autorisation de liste les fichiers dans le dossier |
| w (write) |
Autorise à supprimer ou modifier le contenu du fichier. Permet de supprimer le fichier |
Sur un dossier, il faut également l’attribut “execute” afin d’opérer des modifications |
| x (execute) |
Autorise un fichier d’être lancé comme un processus |
Autorise un utilisateur à entrer dans ce dossier |
L’attribut suivant (1 par exemple) est le nombre de lien symbolique vers ce fichier
Les 2 attributs d’après : root root définissent le propriétaire suivis par le groupe
L’utilisateur qui crée le fichier est considéré comme son propriétaire. Il faut savoir que seul root est habilité à modifier le propriétaire d’un fichier, avec la commande “chown”
Le groupe du fichier sera celui du groupe principal auquel appartient l’utilisateur qui crée ce fichier.
la commande “id” indique l’identité de l’utilisateur actuel, son group principal, et tous les groupes auxquels il appartient. Pour changer le groupe d’un fichier, on utilise la commande “chgrp” seuls root et le propriétaire du fichier peuvent changer le groupe d’un fichier.
Permissions
Seul root et le propriétaire du fichier disposent de la possibilité de modifier les permissions d’un fichier au moyen de la commande chmod
Exemples :
Ajouter les droits d’exécution au propriétaire du fichierchmod u+x monfichier
Supprimer les droits d’écriture pour le groupe :chmod g-w monfichier
Assigner des droits à plusieurs sections des attributs ;chmod o=r,g-w,u+x monfichier
Supprimer toutes les permissionschmod a=- monfichier
La méthode octale reste la plus rapide pour l’attribution, avec
r=4; w=2 et x=1
Pour donner les permissions rwx r-x r-x à un fichier, on va additionner les valeurs :
Owner: 4+2+1 => 7
Group : 4+1 => 5
Other : 4+1 => 5
=> chmod 755 monfichier
Attribut spéciaux -setuid
Cet attribut spécial permet d’appliquer à un fichier exécutable, d’autoriser d’autres utilisateurs à lancer l’exécutable, comme s’il étaient l’utilisateur root.chmod 4000
Exemple avec la commande passwd :
s -> permissions x+setuids (s)
S -> seule la permission setuid existe (pasx)
Attribut spéciaux -setgid
Même chose qu’avec setuid, mais pour le groupe utilisateurchmod 2000
- Appliqué à un fichier exécutable, afin de s’exécuter via le group du propriétaire, au lieu de celui de l'utilisateur qui lance l’exécutable
- Appliqué à un dossier, fait en sorte que le contenu créé dans ce dossier appartient au groupe qui possède le dossier (et pas celui de l’utilisateur qui crée le contenu dans ce dossier)
Attribut spéciaux -sticky
chmod 1000
L’utilité de cet attribut est d’empêcher d’autres utilisateurs de supprimer le contenu d’un autre utilisateur.
Pour supprimer un fichier, il faut les autorisations d’écriture sur le dossier parent. Ainsi, un admin crée un dossier accessible et modifiable par tous les utilisateurs. Tout le monde pourra supprimer le contenu de ce dossier ...
L’utilisation de cette permission sticky permet de définir pour un dossier que :
- L’utilisateur propriétaire d’un fichier, dans ce dossier, pourra supprimer le fichier
- root et l’utilisateur propriétaire du dossier parent pourra aussi
Héritage vs umask
Lorsque l’on crée un sous-dossier sous windows, ce dernier hérite des droits d’accès du dossier parent (par défaut). Il faut savoir que sous linux : NON ! ce n’est pas le cas! En effet le sous-dossier aura les droits créés selon la valeur umask de l’utilisateur créant le sous dossier.
Read vaut 4, write 2, execute 1, rien vaut 0.
Dans le cas de umask, ces valeurs précisent les permissions à supprimer des permissions “maximum” à la création !
Sur un fichier, les permissions maximales sont : rw- rw- rw- soit 666 en octal. La valeur umask de l’utilisateur créant le fichier va donc
permettre de supprimer certaines de ces valeurs! Cette valeur se code avec trois nombres de base en octale.
Ex, Si l’on souhaite que par défaut l’utilisateur sisr, crée des fichiers avec les permissions rw- r-- --- :
- Le premier nombre octal sera 0 (on ne change rien à rw-)
- Le second nombre (groupe) sera 2 (on supprime la permission w, donc 2, il reste r--)
- Le troisième nombre (others) sera 6 (on supprime r soit 4 et w soit 2, il reste ---)
Le umask de l’utilisateur sisr doit donc être 026
Sur un dossier, sans droits d’exécution, il est impossible d’agir dans le dossier, et les éventuels droits en écriture dans ce dossier ne seront pas appliqués.
De ce fait, les permissions “maximales” par défaut accordées à la création d’un dossier sont : rwx rwx rwx soit 777 en octal
Exemple: Le propriétaire doit disposer des droits complets sur le dossier, seulement des droits d’exécution et lecture pour le groupe, et aucun droits pour les autres. Ceci se traduit par : rwx r-x ---
Le umask de l’utilisateur devra retirer les droits en écriture sur le groupe (-2) et les droit rwx à others (-7). Le umask sera donc 027
Umask propose un comportement différent sur les fichiers et sur les dossiers. Mais cette valeur umask est la même pour les fichiers et les dossiers ! On utilise des valeurs “classiques” pour régler umask
Jusqu’ici, nous avons précisé des valeurs sur trois chiffres en base octale. La commande umask affiche le umask de l’utilisateur actuel, mais sur 4 chiffres !
Le premier représente en faite les attributs spéciaux (setuid, setgid, sticky). Cependant, ces attributs spéciaux ne sont pas spécifiables par défaut (lors de la création d’un fichier ou dossier). Il n’est donc pas nécessaire de la préciser ou la calculer lors de l’utilisation de umask.
/!\ Umask n’est utilisé qu’à la création, les fichier existant ne sont pas touchés!
Gestion des archives
Une archive est un fichier contenant un ou plusieurs fichiers ou dossiers, la plupart du temps “compressés” ce afin de diminuer la
consommation d’espace disque. Il existe de nombreux algorithmes de compression et d’archivage, vous connaissez probablement le zip et le rar connu sous windows. Voyons certains des plus utilisés sous les système linux :
Tar
Tar est une très ancienne commande (Tape Archive), utilisée autrefois pour la sauvegarde de contenu sur des bandes magnétiques. Les
premières versions permettaient uniquement l’archivage, mais depuis l'arrivée de gzip (-z) et bzip2(-j) c’est maintenant possible.
Principaux attributs de tar (extension de fichier .tar en général):
- tar -c : Créer une archive
- tar -cf : Créer une archive et spécifier son nom
- tar -cvf : Créer une archive et afficher un diagnostic à l’écran
- tar -cvzf : Créer une archive, compresser avec gzip et afficher le diagnostic
- tar -tf : Lister (option t) le contenu de l’archive en argument (option f)
- tar -vtf : Lister (t) de façon détaillée (v) l’archive (f)
- tar -xf : Extraire (option x) le contenu de l’archive (f)
Gzip et gunzip
Par défaut l’utilisation de gzip remplace un fichier par sa version compressée ! qui aura l’extension “.gz”. Pour éviter ce comportement si l’on
veut conserver le fichier d’origine, on utilise l’option -c qui va rediriger le contenu extrait vers stdout !) il faudra donc faire soi-même la
redirection vers un fichier :
gzip -c monfichieraziper > monfichieraziper.gz
gzip -cr /etc > etc.gz
Gunzip quand à lui effectue l’opération inverse de gzip, il décompresse une archive gz. Et par défaut comme gzip, il remplace le fichier
d’origine “.gz” par sa version décompressé.
bzip2 et bunzip2
Le fonctionnement est similaire au gzip et gunzip, l'algorithme de compression utilisé est différent cependant. L’extension par défaut que l’on
rencontrera sera : bz2. L’option de récursion -r n’est pas disponible non plus, on utilisera le * à la place.
zip et unzip
Même si ce format est surtout utilisé sous windows, linux dispose de son équivalent :
zip ./test.zip ./test/* va compresser le contenu du dossier test dans le fichier test.zip
zip -r /etc/etc.zip /etc va compresser tout le contenu du dossier /etc
xz
xz -z * permet de compresser des fichiers individuellement (autant d’archives que de fichiers) avec l’extension .xz
xz -d permet de décompresser les fichier
cpio
cpio: copy-in copy-out
En mode copy-out (option -o), les fichiers dans un dossier seront recopiés vers une archive
En mode copy-in (option -i) le contenu d’une archive est listé ou copie les fichiers d’une archive vers un dossier.
dd
Permet d’effectuer la copie d’un fichier un d’une partition complète bit à bit. Cela permet de :
- Cloner un disque ou une partition
- Sauvegarder la MBR (master boot record)
- Création d’un fichier d’une taille précise rempli de 0
Recherche de fichier grâce aux commandes locate et find
locate et find sont les deux commandes principales pour chercher des fichiers dans la table d’inode de linux. Elles fonctionnent différemment
mais permettent le même résultat. Nous verrons aussi les commandes whereis / which / type
locate
Cette commande utilise une base de données mise à jour quotidiennement par l’OS. Si vous désirez mettre à jour cette base de données, vous
pouvez utiliser la commande updatedb
Les particularités de cette commande :
- N’affiche que les fichiers lisibles par l’utilisateur
- Très rapide pour la recherche, mais les fichiers récents seront absent à moins d’utiliser l’updatedb
- peut nécessité d’être installé apt-get install locate
find
La commande a besoin de plusieurs choses pour travailler :
- Un nom de dossier comme point de départ de la recherche (sinon travail depuis le dossier courant)
- Pour rechercher un fichier on utilise l’option -name
- Plus lent que locate mais permet de se positionner où l’on veut et n’oubliera aucun fichier
Vous remarquez qu’il y a beaucoup moins de fichiers, c’est qu’il faut utiliser le globing :
exemple : find / -name *passwd*
Voici différents options pour le find :
| Options | Exemple | Description |
| -iname | -iname Hello | recherche les fichiers en ignorant la casse |
| -mtime | -mtime -7 | Les fichiers modifiés il y a moins de 7 jours |
| -mmin | -mmin 5 |
Les fichiers modifiés il y a moins de 5 minutes |
| -size | -size +10M | Les fichiers pesant plus de 10Mo |
| -user | -user sisr | Les fichiers possédés par l’utilisateur sisr |
| -empty | -empty | liste les fichiers vides |
| -type | -type d | Liste les fichiers qui sont des dossiers |
| -maxdepth | -maxdepth 1 | Profondeur de recherche limité à 1, ne parcourt pas les sous-dossiers |
Si l’on veut tous les fichiers créés par l’utilisateur sisr qui s’appelle hosts :
find / -user sisr -name hosts
Ou une syntaxe plus compliquée :
find / -iname ‘ifconfig*’ -o \( -name hosts -user sisr \)
cette commande trouvera à partir du dossier racine :
- Tous les fichiers commençant par ifconfig
- OU Tous les fichiers intitulés hosts appartenant à l’utilisateur sisr
Pour définir sur quels attributs effectués un OU, il faut mettre les attributs entre parenthèses. Le problème c’est que le shell interprète la parenthèse comme un caractère spécial, il faut donc le protéger en utilisant \ devant chaque parenthèse pour dire au shell de ne pas l'interpréter mais de l’envoyer directement à la commande find. Le caractère \ est remplaçable par le ‘ find . -name host* -exec ls -l {} \;
- Trouver tous les fichiers commençant par host dans le dossier actuel et ses sous-dossiers
- Puis lancer la commande ls -l pour chaque fichier trouvé
- le {} permet de passer, fichier par fichier, la main à la commande ls
- Pour que ceci fonctionne, il faut rajouter un ; à la fin de chaque fichier passé en argument, donc \;
whereis et which
- whereis trouve deux binaire au nom de base
- which nous indique que seul bash est utilisé quand on utilise la commande base et non pas bash.bashrc. Ce dernier est un script
automatiquement lancé lorsqu'on se connecte à la ligne de commande en mode interactif.
Swap
Le swap est un espace d’échange qui recueille des données normalement en RAM lorsque l’utilisation de celle-ci dépasse un certain point.
Gérer les espaces d’échange
Voir l’utilisation des espaces d’échanges
cat /proc/swaps
Cela va donner quelque chose comme :
Filename Type Size Used Priority
/dev/dm-3 partition 3911676 3906776 -2
/var/swap file 5242876 310324 -3
Monter et démonter un espace d’échange
Les termes de montage/démontage ne sont pas corrects car les espaces d’échange ne sont pas montés sur le système. Vous ne les verrez pas avec la commande mount.
Pour ne plus utiliser un espace d’échange :
swapoff /dev/dm-3
Cette commande peut prendre un peu de temps car le contenu de l’espace d’échange va être déplacé dans la RAM ou dans un autre espace d’échange, ou oublié par le système s’il n’y a plus de place disponible.
Pour le réutiliser :
swapon /dev/dm-3
L’option -a permet d’agir sur tous les espaces d’échanges connus du système (dans /etc/fstab la plupart du temps. Systemd a un truc pour ça aussi, mais je ne l’ai encore jamais rencontré). Exemple :
swapoff -a
swapon -a
Modifier le recours aux espaces d’échange
Les espaces d’échanges vont être utilisés avec plus ou moins d’agressivité selon la valeur de vm.swappiness de votre système (pour voir cette valeur : sysctl vm.swappiness). Cette valeur peut être comprise entre 0 et 100.
Un nombre élevé veut dire que le noyau va avoir plus tendance à décharger la RAM dans les espaces d’échanges que dans un système avec un nombre bas.
Pour modifier temporairement la valeur :
sysctl -w vm.swappiness=10
Pour la modifier de façon permanente :
echo "vm.swappiness = 10" > /etc/sysctl.d/99-swappiness.conf
sysctl -p /etc/sysctl.d/99-swappiness.conf
(le sysctl -p est là pour appliquer la valeur que vous venez de mettre dans le fichier)
Les différents supports d’espaces d’échanges
On peut avoir du swap avec une partition comme le propose Debian lors de l’installation ou via un fichier swap, comme le fait Ubuntu. On peut aussi avoir du swap… sur la RAM ! (voir plus bas)
L’avantage du fichier sur la partition est sa manipulation plus facile. Je pense en particulier à la modification de la taille du swap.
Créer un fichier swap
C’est excessivement simple : on crée un fichier, on le prépare comme il faut, on le déclare dans /etc/fstab et on l’utilise.
fallocate -l 2G /var/swap
mkswap /var/swap
chmod 600 /var/swap
echo "/var/swap none swap sw 0 0" >> /etc/fstab
swapon /var/swap
Utiliser de la RAM pour l’espace d’échange
Cela paraît contre-intuitif, mais c’est très simple : l’espace d’échange sera compressé et conservé en RAM. Le coût en performances de la compression/décompression des données est, avec nos processeurs actuels, généralement moindre que celui de l’utilisation d’un disque, fut-il SSD : la RAM permet des accès beaucoup, beaucoup plus rapides que n’importe quel disque.
Comme les espaces d’échanges sont utilisés comme de la RAM supplémentaire, mais lente, avoir ceux-ci sur la RAM, mais compressés équivaut plus ou moins à une augmentation de taille de RAM au prix de quelques cycles CPU.
Pour utiliser ce mécanisme, il suffit, sur Debian, d’installer le paquet zram-tools, de modifier /etc/default/zramswap à son goût et de relancer le service zramswap.
Curl
Ceci constitue un petit inventaire des commandes les plus utiles de curl.
Utilisation de base
curl http://example.org
La commande curl télécharge la ressource demandée (qui n’est pas nécessairement une adresse web, car curl est capable de télécharger des ressources d’autres protocoles, comme ftp par exemple) et en affiche le contenu sur la sortie standard, si ce contenu n’est pas un contenu binaire.
Rediriger la ressource vers un fichier
curl http://example.org > fichier.html
curl http://example.org --output fichier.html
curl http://example.org -o fichier.html
Réduire la verbosité de curl
Lorsque la sortie est redirigée vers un fichier, curl affiche une barre de progression donnant certaines indications sur le téléchargement de la ressource (le temps restant, la taille…).
Pour ne pas afficher ces informations, on utilise l’option --silent ou son abbréviation -s.
curl --silent http://example.org -o fichier.html
curl -s http://example.org -o fichier.html
Faire autre chose qu’un GET
Pour utiliser une autre méthode HTTP que GET, on utilise l’option --request ou son abbréviation -X.
curl --request POST http://example.org
curl -X POST http://example.org
Faire une requête HEAD
Si on tente de faire une requête HEAD avec l’option --request, curl affichera un message d’erreur :
Warning: Setting custom HTTP method to HEAD with -X/--request may not work the
Warning: way you want. Consider using -I/--head instead.
Il convient d’utiliser l’option --head ou son abbréviation -I :
curl --head http://example.org
curl -I http://example.org
Pour faire une requête avec authentification HTTP
On spécifie l’identifiant et le mot de passe avec l’option --user ou son abbréviation -u, en les séparant par un caractère :.
curl --user login:password http://example.org
curl -u login:password http://example.org
Forcer la connexion en IPv6 ou en IPv4
On utilise pour cela les options -6 et -4.
curl -6 http://example.org
curl -4 http://example.org
Utilisation avancée
Forcer la connexion sur une autre adresse IP
Il est possible de dire à curl d’utiliser une adresse IP particulière au lieu de la véritable adresse IP d’un domaine. Il faut voir cela comme une alternative à la manipulation du fichier /etc/hosts.
curl --resolve example.org:80:127.0.0.1 http://example.org
curl --resolve "example.org:80:[::1]" http://example.org
La syntaxe de l’option est host:port:addr. Le port est celui qui sera utilisé par le protocole. Spécifier le port 80 pour le protocole https serait inutile : il faut dans ce cas utiliser le port 443.
Forcer la connexion sur une autre adresse IP et un autre port
On utilise pour cela l’option --connect-to, relativement similaire à l’option --resolve. La syntaxe de l’option est host1:port1:host2:port2
curl --connect-to example.org:80:127.0.0.1:8080 http://example.org
curl --connect-to "example.org:80:[::1]:8080" http://example.org
Forcer la connexion depuis une certaine interface réseau
On utilise pour cela l’option --interface suivi du nom d’une interface, d’une adresse IP ou d’un nom d’hôte.
curl --interface wlo1 http://example.org
curl --interface 203.0.113.42 http://example.org
curl --interface example.com http://example.org
Ne pas vérifier la sécurité du certificat du site
Que ce soit parce qu’un certificat est expiré ou parce qu’on utilise un certificat autosigné, on peut avoir besoin que curl effectue bien la requête sans se préoccuper de la validité du certificat utilisé par le site. On utilise alors l’option --insecure ou son abbréviation -k.
curl --insecure https://example.org
curl -k https://example.org
Utiliser un fichier d’autorités de certification spécifique
Si on utilise, par exemple, un certificat autosigné, ou signé par une autorité de certification (AC) personnelle, et qu’on souhaite s’assurer que le certtificat utilisé par le site est bien valide, on peut donner à curl un fichier contenant le certificat public de l’AC (il est possible d’y mettre plusieurs certificats) au format PEM. On utilise l’option --cacert.
curl --cacert fichier_AC.pem https://example.org
On peut aussi utiliser l’option --capath dont l’argument est un dossier contenant des fichiers de certificats d’AC.
curl --capath ~/ACs https://example.org
Sed
C’est l’outil absolu pour modifier du texte en le passant par un pipe ! Ou pour effectuer des changements en masses sur un fichier sans l’ouvrir.
Il est possible de faire des trucs de tarés avec c’est pas juste un truc pour faire des substitutions à coup d’expressions rationnelles, c’est un vrai éditeur de texte, on peut se balader dans le texte, faire des copier/coller, etc.
Syntaxe de base
Avec un fichier :
sed <commande> fichier.txt [fichier2.txt] [fichier3.txt]
En utilisant la sortie d’une autre commande :
find . -name \*.txt | sed <commande>
NB : sed, par défaut, ne modifie pas le fichier utilisé.
Il affichera sur la sortie standard le fichier modifié par la commande passée à sed.
Si on souhaite que le fichier soit modifié, on utilise l’option --in-place ou son abbréviation -i (on peut indifféremment placer l’option avant ou après la commande) :
sed <commande> --in-place fichier.txt
sed -i <commande> fichier.txt
Expression régulières
Si sed est un éditeur de texte (son nom veut dire Stream EDitor) et qu’il est utilisable en lui donnant des commandes équivalentes à « Va à ligne 3, supprime 4 caractères, descend à la ligne suivante… », on l’utilise souvent avec des expressions régulières.
Rappel sur les expressions régulières
Les expressions régulières permettent de rechercher des correspondances avec un motif, écrit avec une syntaxe spéciale.
Les éléments de syntaxe suivants appartiennent aux Perl Compatible Regular Expression (PCRE), qui sont le standard de la très grande majorité des langages de programmation.
sed utilisant une syntaxe légèrement différente, certains caractères devront être échappés (voir plus bas).
NB : les expressions régulières de cette section sont placé entre des / pour les distinguer des chaînes de caractères simples.
.: correspond à un caractère, n’importe lequel././correspondra à tout sauf à une chaîne vide?: quantificateur, modifie la correspondance du caractère qui le précède : celui ci peut être présent zéro ou une fois./a?/correspondra à une chaîne vide ou àa+: quantificateur : le caractère précédent sera présent une ou plusieurs fois./a+/correspondra àa,aa,aaa…*: quantificateur : le caractère précédent sera présent zéro ou plusieurs fois./a*/correspondra à une chaîne vide, àa,aa,aaa…{n}: quantificateur : le caractère précédent sera présentnfois./a{3}/correspondra àaaa{n,m}: quantificateur : le caractère précédent sera présent denàmfois./a{3,5}/correspondra àaaa,aaaaouaaaaa{n,}: quantificateur : le caractère précédent sera présent au moinsnfois./a{3,}/correspondra àaaa,aaaa,aaaaa,aaaaaa…|: séparateur d’expression./bonjour|hello/correspondra àbonjourou àhello[^liste]: correspond aux caractères n’étant pas entre crochets./[^ae]/correspondra à n’importe quel caractère sauf àaet àe[liste]: correspond à un des caractères entre crochets./[ae]/correspondra àaou àe. Pour que le caractère^soit un choix possible, il faut le placer à une autre place que la première place :[liste^],[lis^te]… On peut aussi spécifier des plages de caractères :[0-9a-zA-Z]^: ancre, correspond au début de la ligne./^a/correspondra àasi celui-ci est le premier caractère de la ligne$: ancre, correspond à la fin de la ligne./a$/correspondra àasi celui-ci est le dernier caractère de la ligne(…): groupe l’expression. On peut s’en servir, par exemple, pour capturer des éléments (ce qui permet de les réutiliser plus tard) ou faire des sous-expressions./Bonjour (foo|bar), ça va \?/correspondra àBonjour foo, ça va ?et àBonjour bar, ça va ?
Pour utiliser les caractères de manière littérale (exemple : pour correspondre à un point), on les échappera avec un \. /\./ correspondra au caractère point (.).
Caractères à échapper dans sed
La version GNU de sed utilise les Basic Regular Expression (BRE), qui ont une syntaxe légèrement différentes des PCRE.
Certains caractères doivent donc être échappés dans les BRE, qui sont utilisables tels quels pour des PCRE :
- le quantificateur
+. Exemple :/a\+/ - le quantificateur
?. Exemple :/a\?/ - le quantificateur
{i}. Exemple :/a\{5\}/ - les parenthèses
(…). Exemple :/\(a\)/ - le séparateur d’expressions régulières
|. Exemple :/a\|b/
Effectuer une substitution de texte
La commande à utiliser est 's/expression régulière/substitution/' :
sed 's/foo/bar/' foo.txt
Cette commande remplacera la 1ère occurrence de foo de chaque ligne du fichier par bar.
Si on souhaite remplacer toutes les occurrences de chaque ligne, on emploie le modificateur g :
sed 's/foo/bar/g' foo.txt
Si on ne souhaite remplacer que l’occurrence n°X de chaque ligne :
sed 's/foo/bar/X' foo.txt
## Exemple avec la 2e occurrence :
sed 's/foo/bar/2' foo.txt
Si on ne souhaite remplacer l’occurrence n°X de chaque ligne, ainsi que les suivantes :
sed 's/foo/bar/gX' foo.txt
## Exemple avec la 2e occurrence et les suivantes :
sed 's/foo/bar/g2' foo.txt
Ajouter quelque chose au début de chaque ligne :
sed 's/^/FooBar /' foo.txt
Ajouter quelque chose à la fin de chaque ligne :
sed 's/$/ BazQux/' foo.txt
Si on souhaite que l’expression régulière soit insensible à la casse (ex : s qui correspond aussi à S), on emploie le modificateur i :
sed 's/foo/bar/i' foo.txt
On peut utiliser plusieurs modificateurs en même temps :
sed 's/foo/bar/gi' foo.txt
Pour réutiliser ce qui a correspondu à l’expression régulière dans la chaîne de substitution, on utilise le caractère & :
sed 's/foo/& et bar/' foo.txt
Pour réutiliser ce qui a correspondu à un groupe d’expression, on utilise \1 pour le 1er groupe, \2 pour le 2e groupe… :
sed 's/Bonjour (foo|bar). Il fait beau./Bonsoir \1. À demain./' foo.txt
NB : on peut utiliser d’autres séparateurs que le caractère /, ce qui rend l’écriture d’une commande plus simple si l’expression régulière ou la substitution comportent des / : plus besoin de les échapper.
Exemple :
sed 's@/home/foo@/var/bar@' foo.txt
Supprimer des lignes
Supprimer la ligne n :
sed 'nd' foo.txt
## Exemple avec la 3e ligne :
sed '3d' foo.txt
Supprimer les lignes n à m :
sed 'n,md' foo.txt
## Exemple :
sed '3,5d' foo.txt
Supprimer toutes les lignes sauf la ligne n :
sed 'n!d' foo.txt
## Exemple :
sed '6!d' foo.txt
NB : attention, le caractère ! est un caractère spécial pour bash (et les autres shells).
Si vous utilisez des apostrophes (') pour votre commande sed, tout ira bien, mais si vous utilisez des guillemets doubles ("), il faut l’échapper avec un \.
Supprimer toutes les lignes sauf les lignes n à m :
sed 'n,m!d' foo.txt
## Exemple :
sed '6,8!d' foo.txt
Supprimer les lignes qui correspondent à une expression régulière :
sed '/regex/d' foo.txt
## Exemple :
sed '/foobar/d' foo.txt
Pour supprimer les lignes vides, d’un fichier, il suffit d’utiliser l’expression régulière qui signifie que la ligne est vide :
sed '/^$/d' foo.txt
Pour supprimer la première ligne correspondant à une expression régulière, ainsi que toutes les lignes suivantes :
sed '/regex/,$d' foo.txt
## Exemple :
sed '/foobar/,$d' foo.txt
NB : attention encore une fois aux guillemets doubles, il faudrait échapper $ dans cette commande car le shell essayerait d’interpréter $d comme une variable.
AT
Elle est utilisée pour planifier des actions qui doivent se réaliser ultérieurement et une seule fois. (Une sorte de tache planifié mais sans la répétition).
Par défaut elle n’est pas forcément installé sur votre distribution, pour l’installer :
apt install atSi ca ne marche pas , faites avant un apt-get update.
Puis lancer le service avec :
service atd startou
systemctl start atd.service
systemctl enable atd.serviceExemple d’utilisation :
at now +2 minutesAu prompt, entrer la commande désirée, par exemple :
at> echo “A noter” > /root/exercicesAT.txtPour sortir du prompt, faire un CTRL+D
Le système vous renverra un message de la forme :
Job 1 at JOUR MOI NUMJOUR HEURE ANNEE
Avec la commande atq, vous pouvez visualiser la file de traitement, le premier numéro est le numéro du job dans la file de traitement, suivi de l’horodatage, puis de l’utilisateur ayant lancé le job.
exemple 2 :
at 4:00 AM tomorrow
at> rm /root/exercicesAT.txt
at> <EOT>Pour supprimer un job at, il faut utiliser son numéro obtenu avec atq :
atrm numjobGrâce à l’option -f, suivi du script puis de l’heure on peut lancé directement un bash :
ex :
at -f /root/test.sh 10:30 PMVous pouvez sécuriser la commande at, grâce au fichier /etc/at.allow pour placer dans ce
fichier les utilisateurs autorisés (whitelist)
Ex :
nano /etc/at.allowAwk
Cette commande agit comme un filtre programmable, prenant une série de lignes en entrée (par fichier, ou via l’entrée standard) et écrivant sur la sortie standard (redirigeable). Awk prend en entrée les lignes une par une et choisit les lignes à traiter (ou non) par des expressions rationnelles ou des numéros de lignes. Une fois la ligne sélectionnée, elle est découpée en champs, selon un séparateur d’entrée indiqué dans le programme awk par le symbole FS (par défaut espace et tabulation). Puis les différents champs sont disponibles dans les variables ($1, $2, $3, $NF pour le dernier). Vous pourrez aussi trouver des fichiers .awk qui sont des scripts écrits dans ce langage.awk [-F] '{action-awk}' [ fichier1 fichier2 ..... fichiern ]
La commande prend en paramètre la liste des fichiers à traiter, si des fichiers ne sont pas spécifiés, awk travaillera sur l’entrée standard. On peut donc placé la commande derrière un tube de communication. L’option “-F” permet d'initialiser si besoin la variable “FS” (Field Separator).
Voici une liste des variables prédéfinies au lancement de awk:
| Variables | Valeur par défaut | Rôle |
| RS | Newline (\n) |
Record Separator : Caractère séparateur d’enregistrement (lignes) |
| FS | Suite d’espaces et ou de tabulation | Field Separator : caractères séparateurs de champs. |
| OFS | Espace |
Output Field Separator: Séparateur de champ pour l’affichage |
| ORS | Newline (\b) |
Output Record Separator : Séparateur de ligne pour la sortie |
| ARGV | - |
Tableau initialisé avec les arguments de la ligne de commande (awk inclus) |
| ARGC | - | Nombre d’arguments dans le tableau ARGV |
| ENVIRON | Variables d’environnement exportées par le shell | Tableau contenant les variables d’environnement exportées par le shell. |
| CONVFMT | %.6g | Format de conversion des nombres en string |
| OFTM | %.6g | Format de sortie des nombres. |
| SUBSEP | \0.34 |
Caractère de séparation pour les routines internes de tableaux. |
Attention : Lorsque que la variable FS a plus de 2 caractères, elle sera interprété comme une expression régulière
Voici les variables qui sont initialisées lors du traitement d’une ligne
| Variable | Rôle |
| $0 | Valeur de l’enregistrement courant |
| NF | $1 contient la valeur du 1er champ, $2 du 2ème, ... et $NF le dernier |
| $1,$2, .. $NF |
$1 contient la valeur du 1er champ, $2 du 2ème, ... et $NF le dernier |
| NR |
Number : indice de l’enregistrement courant (NR vaut 1 quand la 1ère ligne est en cours de traitement) |
| FNR |
File Number : indice de l’enregistrement courant relatif au fichier en cours de traitement |
| FILENAME |
Nom du fichier en cours de traitement |
| RLENGTH |
Longueur en string trouvé par la fonction match() |
| RSTART |
Première position du string trouvé par la fonction match |
Exemple d’utilisation :ps -ef| awk ‘{print $1,$8}’
La partie en gras représente entre quote permet d’éviter l’interprétation par le shell et indique à awk quelle fonction exécuter sur le traitement du awk. Les instructions doivent être placées entre accolades. La fonction intégrée print va afficher à l’écran les champs 1 et 8 de chaque ligne.
Voici un autre exemple :ps -ef | awk ‘{print “User : “, $1, “\tCommande : “, $8}’
Critères de sélection :
Il est possible de sélectionner les enregistrements sur lesquels l’action doit être exécutée : awk [-F] 'critère {action-awk}' [fichier1 fichier2 ... fichiern]
Le critère de sélection peut s’exprimer de différentes manières.
Expression régulières :awk -F’:’ ‘/\/bin\/false/ {print $0}’ /etc/passwd
Par défaut, c’est le champ correspondant au $0 qui est mis en correspondance avec
l’expression régulière., mais il est possible de le spécifier avec l’opérateur de concordance
“~” ou de non concordance “!~”.
awk -F ':' '$6 ~ /^\/usr/ {print $0}' /etc/passwd
Test logiques :
Le critère peut être une expression d’opérateurs renvoyant vrai ou faux.
Par exemple, pour afficher uniquement les lignes impaires du fichier /etc/passwdawk -F':' 'NR%2 {print $0}' /etc/passwd
Find
Introduction
Les exemples de ce tuto sont tous à faire en user sauf spécification.
Cette commande permet de faire des recherches de fichier ou de dossier dans une hiérarchie de répertoires.
Par exemple, je voudrais chercher le log messages, mais je sais pas où se trouve ce fichier, faites :
find / -name 'messages'
- résultat de la commande précédente
-
/var/log/messages
Voilà la réponse :
Il se trouve dans le répertoire /var/log.
Nota
Notez l'utilisation des apostrophes afin d'éviter que l'interpréteur de commande n'étende le motif.
Elles sont inutiles dans ce cas-ci mais c'est une bonne pratique de toujours les utiliser afin d'éviter l'extension motif.
Quelques options
| Options | Fonctions |
|---|---|
| -atime n ou +n ou -n | trouve les fichiers auxquels on a accédé il y a strictement n jours, ou plus de n jours, ou moins de n jours |
| -mtime n ou +n ou -n | trouve les fichiers modifiés il y a strictement n jours, ou plus de n jours, ou moins de n jours |
| -maxdepth n | définit le niveau maximum de sous-répertoire à explorer |
| -type l ou d ou f | indique le type de fichier à rechercher (l pour lien symbolique, d pour répertoire (directory), f pour fichier) |
| -name | recherche par motif en respectant la casse |
| -iname | recherche par motif sans respecter la casse |
Recherche simple par nom
Example simple : comment trouver un fichier portant le nom note ?
find / -name 'note'
Décomposition de la commande de l'exemple :
-
“
/” indique que nous voulons chercher notre fichier à partir de la racine. -
“
-name” est l'option qui indique ici que nous voulons spécifier le nom d'un fichier.
Après un long délai d'attente, la recherche se faisant dans toute l'arborescence de la partition, la réponse finit par venir :
- résultat de la commande précédente
-
/home/martin/note
Si l'on n'est pas sûr de la casse (Majuscule ou minuscule) on utilise l'option -iname.
Prenons un autre exemple.
Pour chercher tous les fichiers commençant par note et définir à partir de quel répertoire on souhaite effectuer la recherche on utilise cette syntaxe :
find /home/martin -name 'note*'
Recherche par nom simple & multiple
Maintenant, regardons, encore une fois à l'aide d'un exemple, la syntaxe de la commande find si l'on recherche plutôt un ou plusieurs répertoires.
Je cherche à trouver les répertoires archives dans /media/homebis. Première chose à noter, il peut-être nécessaire de se mettre en root pour avoir accès à tous les répertoires.
find /media/homebis -type d -name 'archives'
Dans ce cas-ci, je demande donc à find de trouver les répertoires
-
option : -type
-
argument : “d” (comme “directory”)
indiquant que l'on cherche un répertoire du nom de archives à partir du répertoire /media/homebis.
La réponse :
- résultat de la commande précédente
-
/media/homebis/martin/textes/mes_archives/Baseball/archives /media/homebis/martin/archives /media/homebis/Documents_gr/Mots_croises/archives /media/homebis/Documents_gr/archives /media/homebis/Documents_gr/mes_fichiers/archives
Autre exemple un peu plus complexe cette fois.
Je désire faire une recherche de tous les fichiers audio de type .mp3 et .ogg
Il existe plus d'une façon d'y arriver.
Voyons comment on peut s'y prendre.
Première façon :
find /home/martin/ \( -name '*.mp3' -o -name '*.ogg' \)
Cela me donnera toute une liste de fichiers /home/martin/…
Deuxième façon :
Une autre manière d'écrire la commande ci-dessus est la suivante :
find -type f -name "*.mp3" -o -name "*.ogg"
Si je tape cette commande en étant dans mon répertoire /home/martin, le résultat sera une liste de fichiers ./….
Il est intéressant de savoir que l'on peut étendre la recherche aux fichiers mp3 et mp4 en remplaçant le 3 par un ?2). La commande deviendrait donc :
find -type f -name "*.mp?" -o -name "*.ogg"
Rechercher pour supprimer
Une fonction intéressante de find est de supprimer en lot les fichiers trouvés.
Il n'est point rare de télécharger ou d'installer de nombreux fichiers qui ne nous servent plus, mais devant le travail pénible de devoir supprimer tous ces fichiers, on repousse au lendemain cette charge. Heureusement grâce à la fonction -delete de find, c'est un pur bonheur.
Paramètre -delete
Exemple, si dans votre home ou autre dossier vous avez beaucoup de fichier .tar.gz qui ne vous servent plus à rien. Il suffit de lancer la commande suivante :
find -iname "*.tar.gz" -delete
Supprimer avec demande de confirmation
Pour une demande de confirmation avant suppression de chaque fichier “.tar.gz” trouvés :
find -iname "*.tar.gz" -ok rm {} \;
Merci à MicP pour cette trouvaille :)
Filtrer en fonction des droits
Une option très pratique est -perm qui permet de sélectionner des fichiers en fonctions de leurs droits.
Les droits peuvent être donné en forme octale, par exemple 0755 ou littérale, u=rwx,g=rw,o=rw.
Voici par exemple comment obtenir la liste de tout les fichiers dans le repertoire /bin qui ont le bit setuid valant 1 :
find /bin -perm /5000 -user root
- résultat de la commande précédente
-
/bin/su /bin/mount /bin/umount /bin/ping /bin/ping6
Cette option est intéressante pour la sécurité. Les fichiers listés dans la commande précédente sont tous exécuté avec les droits root.
perm, sans préfixe, précédé du signe – ou précédé du signe /-
sans préfixe :
le mode du fichier doit être exactement celui passé à l’option -perm.
Par exemple, si on cherche les fichiers ayant le mode u=rwx (0700), tous les fichiers que l’on trouvera auront exactement le mode u=rwx (0700).
-
avec le signe – :
le mode du fichier doit être au moins égal à celui passé à l’option -perm
-u=r (-0400) → u=r ou u=rw ou u=rx ou u=rwx ou u=r,g=x …
-
avec le signe / :
un des modes (user, group ou other) doit être au moins égal à ceux passés à l’option -perm
/u=w,g=w,o=w → u=w ou g=w ou o=w ou u=w,g=w,o=w ou u=rw,g=rwx …
Recherche par motif
Pour rechercher un motif, il faut utiliser la même option, et utiliser les REGEXP.
Voici par exemple la recherche de tous les fichiers terminant par .java dans le dossier courant:
find . -name '*.java'
- résultat de la commande précédente
-
./java/jdk1.5.0_06/demo/applets/Animator/Animator.java ./java/jdk1.5.0_06/demo/applets/ArcTest/ArcTest.java ./java/jdk1.5.0_06/demo/applets/BarChart/BarChart.java ./java/jdk1.5.0_06/demo/applets/Blink/Blink.java ./java/jdk1.5.0_06/demo/applets/CardTest/CardTest.java ...
Rechercher les fichiers n'appartenant pas à l'utilisateur
Il peut parfois être utile de rechercher les fichiers n'appartenant pas à l'utilisateur, en vue de corriger un problème rencontré avec une application (par exemple, un fichier peut appartenir à root au lieu d'appartenir à l'utilisateur ; ce dernier risque de ne pas avoir de droits dessus, ce que peut alors provoquer une erreur dans une application cherchant à modifier le dit fichier).
Pour ce faire, il suffit d'exécuter là commande suivante, où « utilisateur » est à remplacer par votre nom d'utilisateur :
find /home/utilisateur ! -user utilisateur
ou bien, en utilisant des variables :
find $HOME ! -user $USER
Pour avoir davantage d'informations sur les fichiers ainsi trouvés, vous pouvez ajouter l'option ls :
find $HOME ! -user $USER -ls
-exec - Exécuter une commande
La commande find permet d'effectuer toute sorte d'action avec les fichiers trouvés.
Une action très utile est “-exec” qui permet d'exécuter une commande sur les fichiers sélectionnés.
La syntaxe de exec est particulière car il faut pouvoir fournir le nom du fichier trouvé.
À la suite de la commande find habituelle, la syntaxe est :
find /chemin/du/fichier/ <option> <caractéristique fichier> -exec commande {} \;
-
La paire d'accolade est automatiquement remplacée par le nom du fichier,
-
et le point-virgule final permet de marquer la fin de la commande.
Au cas où plusieurs fichiers sont traités dans un même répertoire, pour éviter une relance de la commande après chaque fichier trouvé, remplacer le ; (point-virgule) final par le signe positif : +.
Par exemple ainsi :
find /home/mon_user/test/ -type f -exec echo {} \+
De la même manière, évitez les références vides ou les noms de répertoires exprimés en relatif dans $PATH.
Avec Bash, la paire d'accolades sans espace ({}) ne doit pas être protégée, au contraire du point-virgule qui doit être échappé à l'aide d'un backslash: \;.
Voici par exemple comment on peut compter le nombre de lignes de chaque fichier de code Python de ce site:
find developpement/django/certif -name '*.py' -exec wc -l {} \;
- résultat de la commande précédente
-
1 developpement/django/certif/__init__.py 0 developpement/django/certif/acronym/__init__.py 48 developpement/django/certif/acronym/models.py 82 developpement/django/certif/acronym/tools.py 13 developpement/django/certif/acronym/urls.py 42 developpement/django/certif/acronym/views.py .../...
-
Ici la commande find est utilisée avec l'option
-namepour ne sélectionner que les fichiers se terminant par “.py” (extension de Python). -
La commande “
wc” (qui compte le nombre de ligne avec -l) est invoquée à l'aide “-exec” sur chacun de ces fichiers.
Il existe d'autres variantes de l'exécution de commande comme l'option -execdir qui exécute la commande à partir du répertoire du fichier.
Comme d'habitude vous avez aussi le :
man find
Entièrement disponible à votre curiosité ! ![]()
Tmux
Tmux est un multiplexeur de terminal. Il permet d'utiliser plusieurs terminaux virtuels dans une seule fenêtre de terminal ou une session sur un terminal distant.
Ligne de commande
Lancement
Rien de plus simple :
tmux
Pour nommer une session :
tmux new-session -s <nom de la session>
Voir les sessions tmux existantes
tmux ls
Se rattacher à une session tmux existante
S’il n’y a qu’une seule session, ou si vous voulez vous rattacher à la dernière auquelle vous étiez rattaché :
tmux at
Si vous souhaitez cibler une autre session :
tmux at -t <nom de la session>
Bonus : vous pouvez être plusieurs personnes sur une même session. C’est très pratique quand on doit faire des manipulations à plusieurs, ou dans un but didactique.
Couper une session tmux existante
S’il n’y a qu’une seule session, ou si vous voulez couper la dernière auquelle vous étiez rattaché :
tmux kill-session
Si vous souhaitez cibler une autre session :
tmux kill-session -t <nom de la session>
Aide
Faites Ctrl+b puis ? et tmux vous affichera une liste de commande accesibles avec des raccourcis claviers
Raccourcis claviers usuels
Se détacher de la session tmux
Tmux peut continuer à fonctionner même quand on est déconnecté ou qu’on se détache de la session, ce qui est très pratique pour :
- les connexions réseaux moisies qui vous déconnectent de votre session SSH
- lancer une commande qui va durer longtemps
Ctrl+b puis d
Ouvrir une nouvelle fenêtre
Ctrl+b puis c
Naviguer entre les fenêtres
Ctrl+b puis n (-> next) pour passer à la fenêtre suivante.
Ctrl+b puis p (-> previous) pour passer à la fenêtre précédente
Renommer une fenêtre
Ctrl+b puis ,, vous aurez un prompt dans la barre en bas, tapez ce que vous voulez et appuyez sur la touche Entrée.
Pour sortir du prompt sans valider, appuyez sur la touche Esc.
Créer un nouveau panneau
En coupant la fenêtre horizontalement
Le nouveau panneau sera créé à droite du panneau courant.
Ctrl+b puis %
En coupant la fenêtre verticalement
Le nouveau panneau sera créé en dessous du panneau courant.
Ctrl+b puis "
Zoomer sur un panneau
Si les panneaux sont pratiques, on a parfois envie d’en prendre un et de l’avoir temporairement en plein écran. Pour ça :
Ctrl+b puis z
Et on utilise le même raccourci pour remettre le panneau en petit comme avant.
Naviguer entre les panneaux
Ctrl+b puis utiliser les flèches du clavier
Commandes
Pour entrer en mode commande, faites Ctrl+b puis :.
Vous aurez un prompt dans la barre en bas.
Afficher toutes les commandes disponibles
Utiliser la commande list-commands.
Changer le répertoire de départ
Quand on ouvre un tmux, chaque nouvelle fenêtre ou nouveau panneau s’ouvrira dans le répertoire depuis lequel vous avez créé le tmux.
Pour changer ce répertoire de départ, utiliser la commande attach -c /le/dossier/que/vous/voulez.
Afficher les variables d’environnement de la session
Utilisez la commande show-environnement ou son alias showenv.
Ce sont les variables d’environnement de tmux : il y a aussi les variables d’environnement du système, qui sont copiées par tmux au démarrage d’une session et qui sont fusionnées avec les variables d’environnement de tmux, celles-ci ayant la priorité si une variable existe dans les deux environnements.
Paramétrer une variable d’environnement pour la session
Pour modifier ou ajouter une variable d’environnement à la session, utilisez la commande set-environnement NOM_VAR valeur ou son alias setenv NOM_VAR valeur.
Copie de Fichiers avec scp
Voici la syntaxe générale de la commande scp :
scp [[user@]host1:]file1 ... [[user@]host2:]file2
Cette commande permet de copier un fichier d'une machine host1 vers la machine host2... Ccnsultez la manuel pour plus de détails : man scp. En général, on l'utilise plus simplement pour copier un fichier file1 de la machine locale vers le home (~) distant de user sur la machine cible host2 :
scp file1 user@host2:~/Ou inversement, pour copier un fichier file1 de la machine distante host1 vers le répertoire courant (.) de votre machine locale : locale :
scp user@host1:~/file1 .Nota Bene : Dans chaque commande, il faut remplacer user par le login associé à votre compte sur la machine source / cible.
Mise à jours automatique avec unattended-upgrades
Objectif
Configurer des mises à jour de sécurité automatiques sur une machine Debian/Proxmox à l’aide de unattended-upgrades.
Installation des paquets
apt update
apt install unattended-upgrades apt-listchanges -y
Activation automatique avec dpkg-reconfigure
dpkg-reconfigure unattended-upgrades
Répondre "Oui" à la question pour activer les mises à jour de sécurité automatiques.
Vérification et configuration automatique
L’outil dpkg-reconfigure crée ou met à jour ce fichier :
/etc/apt/apt.conf.d/20auto-upgrades
Avec un contenu équivalent à :
APT::Periodic::Update-Package-Lists "1";
APT::Periodic::Unattended-Upgrade "1";
APT::Periodic::AutocleanInterval "7";
Test de fonctionnement
Lancer une simulation de mise à jour automatique :
unattended-upgrade --dry-run --debug
Fichier de configuration avancée (facultatif)
Il est possible de personnaliser les origines de mise à jour et les paquets à exclure dans :
/etc/apt/apt.conf.d/50unattended-upgrades
Par exemple, pour Proxmox, on peux ajouter une blacklist :
Unattended-Upgrade::Package-Blacklist {
"proxmox-ve";
"pve-kernel";
"pve-manager";
"pve-qemu-kvm";
"lxc-pve";
"libpve*";
};
Et activer les origines pertinentes si on veux inclure les mises à jour Proxmox (avec ou sans abonnement) :
Unattended-Upgrade::Allowed-Origins {
"Debian stable";
"Debian stable-updates";
"Debian-security stable-security";
"PVE pve-no-subscription"; // ou "PVE pve-enterprise"
};
SSH - Ajout de la 2FA
La double authentification permet d'ajouter au système d'authentification classique (mot de passe ou clé SSH) une couche supplémentaire unique avec un code unique générer régulièrement.
Personnellement je l'utilise sur toutes les machines ou le SSH est activé sur le port publique.
Installation du module PAM Google Authenticator
! Ce produit est développé par Google mais aucune information personnelle ou donnée de tracking n'est envoyé à Google lors de son installation ou de son utilisation ! #RGPD
Le module s'installe de la manière la plus classique:
apt install libpam-google-authenticator -yConfiguration de PAM
Modifier le fichier /etc/pam.d/sshd pour ajouter:
auth required pam_google_authenticator.soConfiguration de sshd
Modifier le fichier /etc/ssh/sshd_config pour modifier la ligne:
ChallengeResponseAuthentication noPar:
ChallengeResponseAuthentication yesInitialisation de la 2FA
Il faut être connecté avec le compte sur lequel on souhaite activer la 2FA en ssh !
Lancer la commande suivante:
google-authenticatorEt répondre aux questions de la manière suivante:
Do you want authentication tokens to be time-based (y/n) y
# A ce moment le QR-Code apparait, pour évité qu'un écran petit cache le code après avoir répondu au question, il est recommander d'ajouter le code maintenant avec la "Ajout de la 2FA sur son mobile"
Do you want me to update your "/root/.google_authenticator" file? (y/n) y
# La réponse à la prochaine question dépant de vous
# Si vous réponder 'n' vous accepter qu'un code puisse être utiliser plusieurs fois
Do you want to disallow multiple uses of the same authentication
token? This restricts you to one login about every 30s, but it increases
your chances to notice or even prevent man-in-the-middle attacks (y/n) y
# La question suivante défini la possibilité d'utiliser un code dans les 4 minutes qui suive afin de compenser une de-synchronisation de temps
# Répondre 'y' autorise les 4 minutes mais augment les chances d'attaque
By default, a new token is generated every 30 seconds by the mobile app.
In order to compensate for possible time-skew between the client and the server,
we allow an extra token before and after the current time. This allows for a
time skew of up to 30 seconds between authentication server and client. If you
experience problems with poor time synchronization, you can increase the window
from its default size of 3 permitted codes (one previous code, the current
code, the next code) to 17 permitted codes (the 8 previous codes, the current
code, and the 8 next codes). This will permit for a time skew of up to 4 minutes
between client and server.
Do you want to do so? (y/n) n
# Ici on indique si oui ou non on veut limité le nombre d'essaie à la 2FA
# Très fortement déconseillier de mettre non car cela autoriserais un robot à faire une attaque brut-force
If the computer that you are logging into isn't hardened against brute-force
login attempts, you can enable rate-limiting for the authentication module.
By default, this limits attackers to no more than 3 login attempts every 30s.
Do you want to enable rate-limiting? (y/n) yRedémarrage du service sshd
Redémarrer le service sshd afin d'appliquer les paramètres:
systemctl restart sshdConnexion Clé SSH
Génération de la paire de clés:
Pour générer la paire de clé utiliser ssh-keygen. On préfèreras générer une clé en ECSDA d'une longueur supérieur à 256 bits pour respecter les recommandations R9 et R10 du guide de l'ANSSI sur OpenSSH. La clé publique est facilement reconnaissable car elle se fini en .pub.
ssh-keygen -t ecdsa -b 521Il est possible de protéger les clés avec une phrase de passe. Cette phrase de passe doit être rentrée à chaque utilisation de la clé, ce qui n'est pas une bonne chose pour l'automatisation. Pour palier ce problème il est possible d'utiliser l'agent SSH ssh-agent qui va servir de trousseau de clé.
Partage de la clé publique
La clé publique est celle qui doit être présente dans le fichier authorized_keys sur le serveur distant. Il est recommander d'utiliser ssh-copy-id qui vas créer les fichier nécessaires et ajouter la clé automatiquement. Ce dernier n'est pas toujours disponible, alors il faut s'orienter vers des méthodes plus manuel.
ssh-copy-id:
ssh -i ~/.ssh/mykey user@hostManuel:
Commencer par copier la clé publique sur le serveur distant, pas exemple avec scp:
scp mykey.pub user@host:/home/userPuis ajouter la clé au fichier authorized_keys:
echo -e "\n"`cat mykey.pub` >> .ssh/authorized_keysAgent SSH:
L'agent SSH permet de garder les clés de manière protégé en mémoire pour qu'elles puissent être utilisées sans entrer la phrase de passe. (Les clés sont gardée même après un redémarrage.)
Sous Windows :
Élévation de privilège requise
Sous Windows l'agent SSH est désactivé par défaut. Il est possible de l'activer avec une commande Powershell:
Set-Service ssh-agent -StartupType Automatic Cette commande est l'équivalent d'aller dans le gestionnaire des services et de passer le démarrage du service OpenSSH Authentication Agent en "Automatique". Le démarrage "Automatique" veut dire que le service démarreras au démarrage de Windows.
Si l'on veut uniquement démarrer l'agent juste pour la durée de la session il est nécessaire de premièrement activer le service, puis de le démarrer :
Set-Service ssh-agent -StartupType Manual; Start-Service ssh-agentComment changer l’ordre du boot avec GRUB
Après l’installation d’un nouveau système d’exploitation avec une nouvelle partition sur votre système, il peut arriver que vous vouliez changer l’ordre de démarrage des systèmes d’exploitation.
Donc, d’abord il faut vérifier l’ordre par défaut.
Pour ce faire, il faut regarder au démarrage de votre ordinateur, il affiche pendant quelques secondes le choix pour les différents systèmes d’exploitation.
Regardez bien l’ordre !
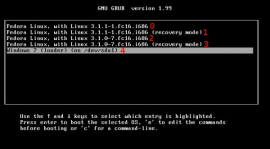
Comme le montre ma capture d’écran, il faut noter que la première ligne correspond à 0, la deuxième à 1, et ainsi de suite.
Maintenant tapez cette commande :
sudo gedit /boot/grub/grub.cfgCherchez « set default= »0″ »
modifiez cette valeur par le numéro de la partition du système qui doit se lancer par défaut (pour moi c’est le numéro 4 si je veux que Windows se lance par défaut au lieu de Fedora).
Enregistrez votre fichier et redémarrez l’ordinateur et normalement l’ordre de boot est changé
How to Add a Directory to PATH in Linux
When you type a command on the command line, you’re basically telling the shell to run an executable file with the given name. In Linux, these executable programs, such as ls , find , file , and others, usually live inside several different directories on your system. All file with executable permissions stored in these directories can be run from any location. The most common directories that hold executable programs are /bin, /sbin, /usr/sbin, /usr/local/bin and /usr/local/sbin.
But how does the shell knows, what directories to search for executable programs? Does the shell search through the whole filesystem?
The answer is simple. When you type a command, the shell searches through all directories specified in the user $PATH variable for an executable file of that name.
This article explains how to add directories to the $PATH variable in Linux systems.
What is $PATH in Linux ?
The $PATH environmental variable is a colon-delimited list of directories that tells the shell which directories to search for executable files.
To check what directories are in your $PATH, you can use either the printenv or echo command:
echo $PATHThe output will look something like this:
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
If you have two executable files sharing the same name located in two different directories, the shell will run the file that is in the directory that comes first in the $PATH.
Adding a Directory to $PATH
There are situations where you may want to add other directories to the $PATH variable. For example, some programs may be installed in different locations, or you may want to have a dedicated directory for your personal scripts but be able to run them without specifying the absolute path to the executable files. To do this, you simply need to add the directory to your $PATH.
Let’s say you have a directory called bin located in your Home directory in which you keep your shell scripts. To add the directory to your $PATH, type in:
export PATH="$HOME/bin:$PATH"The export command will export the modified variable to the shell child process environments.
You can now run your scripts by typing the executable script name without specifying the full path to the file.
However, this change is only temporary and valid only in the current shell session.
To make the change permanent, you need to define the $PATH variable in the shell configuration files. In most Linux distributions, when you start a new session, environment variables are read from the following files:
-
Global shell-specific configuration files such as
/etc/environmentand/etc/profile. Use this file if you want the new directory added to all system users$PATH. -
Per-user shell-specific configuration files. For example, if you use Bash, you can set the
$PATHvariable in the~/.bashrcfile. If you are using Zsh the file name is~/.zshrc.
In this example, we’ll set the variable in the ~/.bashrc file. Open the file with your text editor and add the following line at the end of it:
nano ~/.bashrcexport PATH="$HOME/bin:$PATH"Save the file and load the new $PATH into the current shell session using the source command:
source ~/.bashrcTo confirm that the directory was successfully added, print the value of your $PATH by typing:
echo $PATHRemoving a Directory from $PATH
To remove a directory from the $PATH variable, you need to open the corresponding configuration file and delete the directory in question from the $PATH variable. The change will be active in the new shell sessions.
Another rare situation is if you want to remove a directory from the $PATH only for the current session. You can do that by temporarily editing the variable. For example, if you want to remove the /home/lina/bin directory from the $PATH variable, you would do the following:
PATH=$(echo "$PATH" | sed -e 's/:\/home\/lina\/bin$//')In the command above, we’re passing the current $PATH variable to the sed command, which will remove the specified string (directory path).
If you temporarily added a new directory to the $PATH, you can remove it by exiting the current terminal and opening a new one. The temporary changes are valid only in the current shell session.
Conclusion
Adding new directories to your user or global $PATH variable is pretty simple. This allows you to execute commands and scripts stored on nonstandard locations without needing to type the full path to the executable.
The same instructions apply for any Linux distribution, including Ubuntu, CentOS, RHEL, Debian, and Linux Mint.
Ajouter un MOTD dynamique
C’est quoi un MOTD ?
Comme indiqué plus haut, lorsque l’on se connecte sur une machine Linux (Débian dans mon cas) en ligne de commande (ici en SSH donc), il y a tout un message qui s’affiche. C’est celui-ci que l’on va modifier afin d’y afficher les valeurs de notre choix !
MOTD de base
Dans mon cas, je souhaite afficher le nom de la machine, ainsi que quelques informations sur la machine comme le CPU, la mémoire libre, l’adresse IP, etc…
Voici un exemple du résultat que j’ai obtenu.
MOTD Personnalisé
Comment changer ce fameux MOTD ?
En fait, lorsque l’on creuse, on se rend compte que c’est intégré nativement à Linux (je le rappelle, dans mon cas ce sont des distributions Débian). Pour faire simple, il suffit de créer des scripts, et de les mettre dans un dossier bien spécifique. Lorsque c’est fait, ils seront automatiquement exécutés lorsque vous allez vous connecter.
Ici, je souhaite avoir le nom de ma machine avec une police originale et en couleur. Je vais donc commencer par installer l’utilitaire qui permet d’écrire de cette façon, à savoir « figlet« .
Pour cela, il faut saisir apt-get update && apt-get install figlet
Une fois installé, vous pouvez tester afin de valider le bon fonctionnement via la commande figlet test par exemple.
Exemple d’utilisation de Figlet
On se déplace ensuite dans le dossier /etc dans lequel doit se trouver un dossier nommé update-motd.d.
Le dossier est bien présent
Si celui-ci n’existe pas, il faut alors le créer et lui donner les droits en exécution via mkdir /update-motd.d && chmod 644 /update-motd.d.
Si ce dossier existe déjà, vous pouvez vous apercevoir qu’il y a déjà un script 10-uname. Personnellement je ne vais pas l’utiliser je vais donc le supprimer via rm 10-uname.
Le principe est simple, tous les scripts se trouvant dans ce dossier sont exécutés lors de la connexion. Il suffit de les nommés 00-xxx, 10-xxx, 20-xxx, etc. pour qu’ils soient exécutés dans l’ordre de votre choix.
Pour créer mon MOTD, je me suis basé sur plusieurs sources (je vous les donnerais toutes à la fin de l’article). Dans l’une de ces sources, il y avait un fichier permettant d’utiliser de la couleur, ce qui est plus sympa !
Je vais donc créer ce fameux fichier, dans mon dossier /etc/update-motd.d via la commande nano colors.
On va ensuite y coller le code suivant :
NONE="\033[m"
WHITE="\033[1;37m"
GREEN="\033[1;32m"
RED="\033[0;32;31m"
YELLOW="\033[1;33m"
BLUE="\033[34m"
CYAN="\033[36m"
LIGHT_GREEN="\033[1;32m"
LIGHT_RED="\033[1;31m"On va maintenant passer au script pour afficher le nom du serveur. Toujours dans le dossier /update-motd.d nous allons créer un fichier 00-hostname via nano 00-hostname et dont le code est le suivant :
#!/bin/sh
. /etc/update-motd.d/colors
printf "\n"$LIGHT_RED
figlet " "$(hostname -s)
printf $NONE
printf "\n"Ensuite, on passe au second fichier, qui se nomme 10-banner, et qui va afficher la version Debian qui est utilisée. On le créer donc avec la commande nano 10-banner, et on y ajoute le code suivant :
#!/bin/bash
#
# Copyright (C) 2009-2010 Canonical Ltd.
#
# Authors: Dustin Kirkland <kirkland@canonical.com>
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License along
# with this program; if not, write to the Free Software Foundation, Inc.,
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
. /etc/update-motd.d/colors
[ -r /etc/update-motd.d/lsb-release ] && . /etc/update-motd.d/lsb-release
if [ -z "$DISTRIB_DESCRIPTION" ] && [ -x /usr/bin/lsb_release ]; then
# Fall back to using the very slow lsb_release utility
DISTRIB_DESCRIPTION=$(lsb_release -s -d)
fi
re='(.*\()(.*)(\).*)'
if [[ $DISTRIB_DESCRIPTION =~ $re ]]; then
DISTRIB_DESCRIPTION=$(printf "%s%s%s%s%s" "${BASH_REMATCH[1]}" "${YELLOW}" "${BASH_REMATCH[2]}" "${NONE}" "${BASH_REMATCH[3]}")
fi
echo -e " "$DISTRIB_DESCRIPTION "(kernel "$(uname -r)")\n"
# Update the information for next time
printf "DISTRIB_DESCRIPTION=\"%s\"" "$(lsb_release -s -d)" > /etc/update-motd.d/lsb-release &Maintenant, je souhaite dans mon cas, ajouter différentes informations comme le CPU, la charge du système, la RAM libre, etc. J’ai donc pour cela, créé un script que j’ai nommé 20-sysinfo dont le code est le suivant :
#!/bin/bash
proc=`cat /proc/cpuinfo | grep -i "^model name" | awk -F": " '{print $2}'`
memfree=`cat /proc/meminfo | grep MemFree | awk {'print $2'}`
memtotal=`cat /proc/meminfo | grep MemTotal | awk {'print $2'}`
uptime=`uptime -p`
addrip=`hostname -I | cut -d " " -f1`
# Récupérer le loadavg
read one five fifteen rest < /proc/loadavg
# Affichage des variables
printf " Processeur : $proc"
printf "\n"
printf " Charge CPU : $one (1min) / $five (5min) / $fifteen (15min)"
printf "\n"
printf " Adresse IP : $addrip"
printf "\n"
printf " RAM : $(($memfree/1024))MB libres / $(($memtotal/1024))MB"
printf "\n"
printf " Uptime : $uptime"
printf "\n"
printf "\n"Comment afficher de façon plus sympa les caractéristiques CPU. En effet, lorsque que l'ont a plusieurs coeurs,on fini par avoir plusieurs fois la ligne qui s’affichait. Ici, cela permet d’indiquer le nombre de coeurs/processeurs avant le type de CPU. Dans le script 20-sysinfo, il faut remplacer la ligne proc par :
proc=`(echo $(more /proc/cpuinfo | grep processor | wc -l ) "x" $(more /proc/cpuinfo | grep 'model name' | uniq |awk -F":" '{print $2}') )`Maintenant, nous devons rendre ces fichiers exécutable, afin qu’ils soient interprétés à la connexion. Pour cela, on utilise la commande chmod 755 00-hostname, même chose pour les deux autres fichiers en changeant bien sûr le nom du fichier.
Nos 3 scripts sont maintenant exécutables.
Il nous reste à supprimer l’ancien MOTD, via la commande rm /etc/motd. Il faut maintenant le récréer via la commande ln -s /var/run/motd /etc/motd.
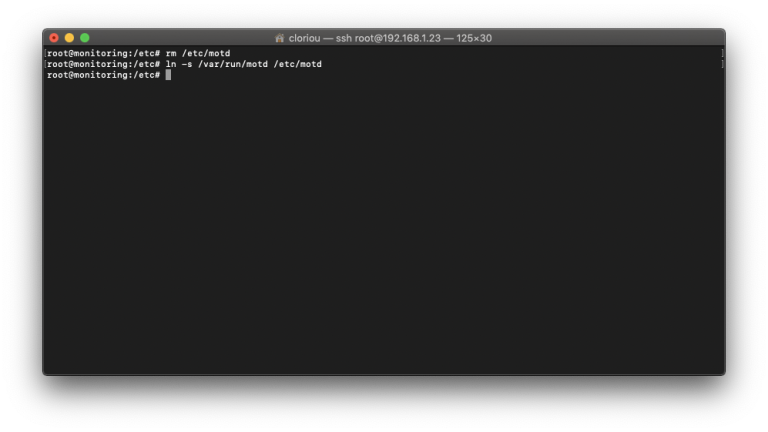
Suppression de l’ancien MOTD
Et voilà, à partir de maintenant, lors de la prochaine connexion en SSH, vous devriez avoir votre MOTD, qui correspond aux différents scripts que nous avons vus juste avant.
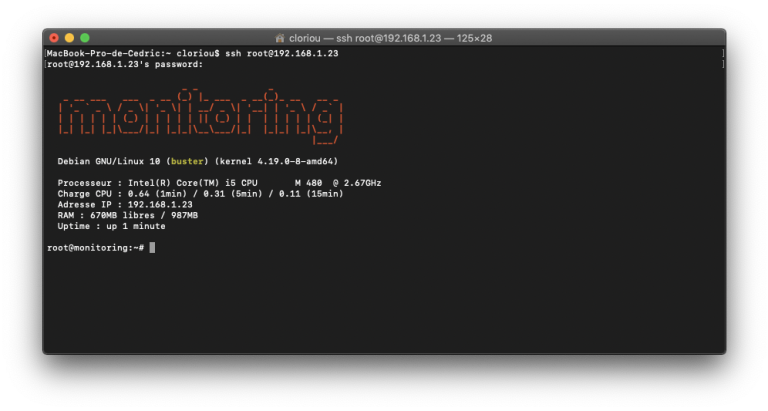
Voilà notre beau MOTD 🙂
Ajouter des couleurs à ses scripts shell
Les codes
Remise à zéro du formatage
NC='\033[0m'
Couleurs de base
BLACK='\033[0;30m'
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[0;33m'
BLUE='\033[0;34m'
PURPLE='\033[0;35m'
CYAN='\033[0;36m'
WHITE='\033[0;37m'
En couleur et en gras
En gras, c’est bold en anglais, d’où le préfixe B.
BBLACK='\033[1;30m'
BRED='\033[1;31m'
BGREEN='\033[1;32m'
BYELLOW='\033[1;33m'
BBLUE='\033[1;34m'
BPURPLE='\033[1;35m'
BCYAN='\033[1;36m'
BWHITE='\033[1;37m'
Utilisation
RED='\033[0;31m'
NC='\033[0m'
echo -e "${RED}Hello world${NC}"
On notera ici trois choses :
- l’encadrement de la variable par des accolades, pour la séparer du texte (sinon le shell essayerait d’interpréter la variable
$REDHello, qui n’existe pas) ; - l’utilisation de l’option
-ed’echo : selon le shell utilisé, le comportement sera différent (les shells bash, dash, zsh (et les autres aussi, sans doute) utilisent leur propre commandeecho). L’option-eest nécessaire pour activer l’interprétation des backslash pour/usr/bin/echo, pas pour leechode zsh. Dans le doute, il faut utiliser cette option. - l’utilisation de la variable de remise à zéro à la fin de la phrase. Certains shells vont conserver le changement de formatage de texte après le
echo(bash, dash), d’autres non (zsh). Encore une fois, dans le doute, on remet le formatage à zéro.
sachant que printf est plus standardisé, donc au comportement plus constant entre les shells.
Avec printf, ça donne :
RED='\033[0;31m'
NC='\033[0m'
printf "${RED}Hello world${NC}\n"
À noter, le \n final, car printf ne fait pas de retour à la ligne automatiquement.
Exécuter une action à la mise en veille / au réveil
Systemd
On mettra un script dans /lib/systemd/system-sleep/ :
Exemple de script :
#!/bin/sh
case "${1}" in
pre)
echo "Suspension ou hibernation"
;;
post)
echo "Réveil ou dégel"
;;
esac
Le 2e argument ($2) pourra être suspend, hibernate, suspend-then-hibernate ou hybrid-sleep, si vous voulez effectuer des actions différentes pour ces cas.
Pour plus d’informations, voir la page de manuel de systemd-sleep.
InitV
On mettra un script dans /etc/pm/sleep.d/.
Exemple de script :
#!/bin/sh
case "${1}" in
suspend|hibernate)
echo "Suspension ou hibernation"
;;
resume|thaw)
echo "Réveil ou dégel"
;;
esac
Antisèche
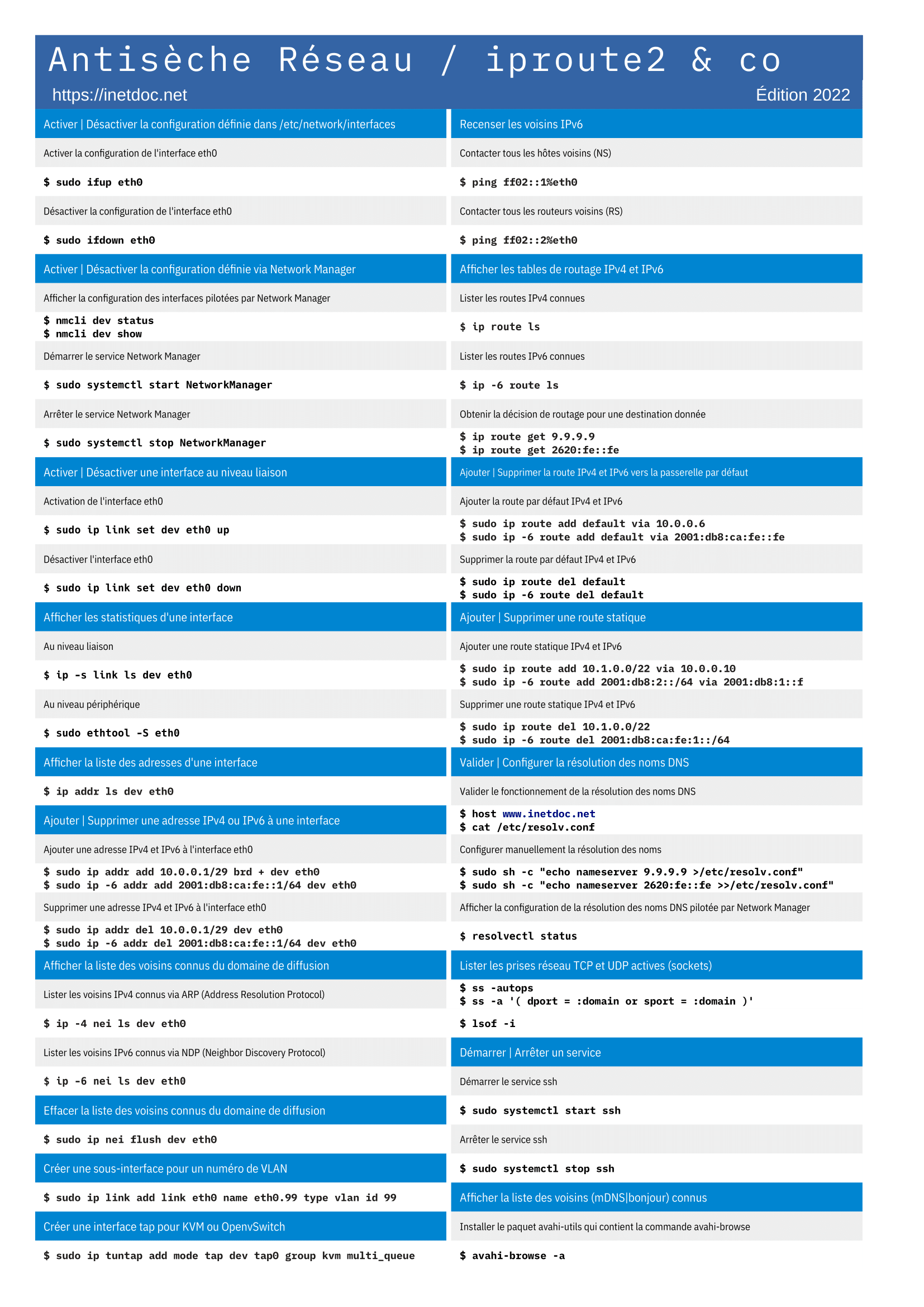
Linux General Cheat Sheets
Information système
| Commande | Commentaire |
|---|---|
| uname -a | Afficher les informations systèmes de linux |
| uname -r | Afficher la version du noyau |
| uptime | Afficher le temps d'activité du système et affiche la charge |
| hostname | Affiche le nom d'hôte de la machine |
| hostname -I | Affiche l'adresse IP de l'hôte |
| last reboot | Afficher l'historique des redémarrages |
| date | Afficher la date et l'heure du système |
| cal | Affiche le calendrier du mois |
| w | Affiche qui est en ligne |
| whoami | Affiche où nous sommes loggué en tant que qui |
Information matérielle
| Commande | Commentaire |
|---|---|
| dmesg | Affiche les messages du noyau |
| cat /proc/cpuinfo | Affiche les informations du CPU |
| cat /proc/meminfo | Affiche les informations de la RAM |
| free -h | Affiche la mémoire libre et utilisé (-h pour lisible par l'homme, -m for MB et -g pour GB) |
| lspci -tv | Affiche les périphériques PCI |
| lsusb -tv | Affiche les périphériques USB |
| dmidecode | Affiche les information DMI/SMBIOS (informations systèmes) depuis le BIOS |
| hdparm -i /dev/sda | Affiche les informations du disque /dev/sda |
| hdparm -rT /dev/sda | Faire un test de vitesse de lecture sur le disque /dev/sda |
| badblocks -s /dev/sda | Test le disque /dev/sda pour d'éventuels blocks défectueux |
ls - Lister le contenu d'un répertoire
Permet de lister le contenu d'un répertoire
Syntaxe :
ls <option> répertoire| Option | Commentaire |
|---|---|
| -a | Lister tout le répertoire (y compris fichier caché) |
| -l | Afficher le répertoire sous forme de tableau, avec permission, ... |
| -i | Affiche les inodes |
| -h | Affiche la taille dans un format lisible par l'homme (Mo par exemple) |
| -R | Liste également les sous-répertoires |
| -s | Affiche la taille des répertoires |
pwd - Afficher le répertoire courant
Affiche le répertoire dans lequel on se situe.
Syntaxe :
pwdmkdir - Créer un répertoire
Créer un répertoire.
mkdir -p /chemin/répertoire/à/créer| Option | Commentaire |
|---|---|
| -p | Créer les répertoires parents si ces derniers n'existent pas |
Exemple : Je souhaite créer un répertoire truc dans /home/user1/test1, mais le fichier test1 n'existe pas.
Syntaxe :
mkdir -p /home/user1/test1/truccd - Changer de répertoire
Permet de se déplacer dans l'arborescence
Syntaxe :
cd /répertoire/de/destinationcat - Afficher le contenu d'un fichier
Permet d'ouvrir un fichier et d'afficher son contenu.
Syntaxe :
cat <option> fichier| Option | Commentaire |
|---|---|
| -b | Numéroter toutes les lignes non vides |
| -n | Numéroter toutes les lignes |
df - Afficher la taille d'un répertoire
Permet d'afficher la taille d'un répertoire.
Syntaxe :
df <option> répertoire| Option | Commentaire |
|---|---|
| -h | Permet d'obtenir un résultat plus lisible pour un humain (ex Mo, Ko,...) |
| -i | Affiche les inodes |
| -k | Affiche le résultat en kilobytes |
| -m | Affiche le résultat en megabytes |
| -d n. | Affiche la taille des sous-répertoires jusqu'au nème |
mv - Déplacer un fichier ou dossier
Permet de déplacer un fichier ou un répertoire.
Syntaxe :
mv <option> /chemin/source /chemin/destination| Option | Commentaire |
|---|---|
| -f | Forcer le déplacement |
| -i | Demander la confirmation de l'utilisateur |
rm - Supprimer un fichier ou dossier
Permet de supprimer un fichier ou un dossier
Syntaxe :
rm <option> /chemin/truc/a/supprimer| Option | Commentaire |
|---|---|
| -d | Efface un répertoire |
| -f | Force la suppression |
| -i | Demande confirmation à l'utilsateur (Inutile avec -f) |
| -r | Récursif |
groups - Afficher les groupes d'appartenance d'un utilisateur
Permet d'afficher dans quels groupes se trouve l'utilisateur
Syntaxe :
groups utilisateurpasswd - Changer le mot de passe
**Permet de changer le mot de passe d'un utilisateur
Syntaxe :
passwd <option> utilisateur| Option | Commande |
|---|---|
| -d | Supprimer le mot de passe |
| -e | Faire expirer le mot de passe |
| -i | Rendre un compte inactif |
| -l | Verouille le mot de passe et empêche sa modification par l'utilisateur |
| -S | Affiche le status du compte |
| -u | Déverouille un mot de passe |
Faire un rechercher remplacer récursif :
Remplacer "texte1" par "texte2".
find . -name "*" -exec sed -i 's/texte1/texte2/g' {} \;Rechercher une chaine présente dans des fichiers d'un dossier de manière récursive :
grep -rnw /PATH/TO/THE/FOLDER -e 'MA-CHAÎNE'Répéter une commande en boucle :
watch macommande [options]Couper le début d'une réponse
cat /mon/fichier | cut -c 19-
--> On retire les 18 premiers charsEnvoyer une commande à un autre utilisateur :
su - UTILISATEUR -c "MA COMMANDE"Mettre à jour à la fois les paquets mais aussi la version de la distribution :
apt-get full-upgradeLister les IP D'un CIDR :
nmap -sL -n 10.10.64.0/27 | awk '/Nmap scan report/{print $NF}'
# Résultat :
10.10.64.0
10.10.64.1
10.10.64.2
10.10.64.3
10.10.64.4
10.10.64.5
10.10.64.6
10.10.64.7
10.10.64.8
10.10.64.9
10.10.64.10
10.10.64.11
10.10.64.12
10.10.64.13
10.10.64.14
10.10.64.15
10.10.64.16
10.10.64.17
10.10.64.18
10.10.64.19
10.10.64.20
10.10.64.21
10.10.64.22
10.10.64.23
10.10.64.24
10.10.64.25
10.10.64.26
10.10.64.27
10.10.64.28
10.10.64.29
10.10.64.30
10.10.64.31Supprimer les dossier datant de plus de quinze jours :
DIR=/backup
find $DIR -type d -ctime +15 -exec rm -rf {};Savoir le load du proc :
cat /proc/loadavgInstaller un environnement graphique :
apt-get install task-lxde-desktopAjouter un utilisateur à la liste des Sudoers :
Avec l'utilisateur Root exécutez la commande ci-dessous :
sudo usermod -a -G sudo <username>
L'utilisateur peut désormais faire la commande sudo !
Mettre une adresse IP fixe sur Linux :
On modifie le fichier situé dans /etc/network/interfaces :
nano /etc/network/interfaces
auto eth1
iface eth1 inet static
address 192.168.0.42
network 192.168.0.0
netmask 255.255.255.0
gateway 192.168.0.1Puis on redémarre le service :
service networking restartL'IP est désormais fixe !
Grep toutes les IPS d'un fichier
cat mon_super_fichier | grep -E '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'Savoir son adresse IP d'une manière lisible :
ip -br aSavoir la taille totale de RAM non-utilisée :
freeDétails de la RAM :
sudo dmidecode -t 17Savoir le nombre de processeurs :
nprocDétails du CPU :
lscpuChanger le fuseau d'horaire :
dpkg-reconfigure tzdataChanger le fuseau horaire sans intéraction :
ln -fs /usr/share/zoneinfo/Europe/Paris /etc/localtime
dpkg-reconfigure --frontend noninteractive tzdataGénérer une chaine aléatoire :
< /dev/urandom tr -dc _A-Z-a-z-0-9 | head -c${1:-32};echo;Filtrer le résultat d'une commande : Récupérer la X ième collone
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b47869c06afa local_ansible:latest "tail -F anything" 4 days ago Up 4 days XXXXXXXXXX.1.xkdfozjzesx3i9tiiwi7v4mx2
98d251874810 local_ansible:latest "tail -F anything" 4 days ago Up 4 days XXXXXXXXXX.1.30q690xvddk600wt35tuii2qr
e59db4bf005e local_ansible:latest "tail -F anything" 4 days ago Up 4 days XXXXXXXXXX.1.wf6mpbnyl3fmvvl1dm6rvgx7q
d5bb4b393058 local_ansible:latest "tail -F anything" 4 days ago Up 4 days XXXXXXXXXX.1.ug7xuyrdx61jz2hyir01i85dl
c7e24c57b1c3 local_ansible:latest "tail -F anything" 4 days ago Up 4 days XXXXXXXXXX.1.xgn2wopz174n4vsq8sfu1hbuz
docker ps | awk '{print $1}'
CONTAINER
b47869c06afa
98d251874810
e59db4bf005e
d5bb4b393058
c7e24c57b1c3$1 représente la première collone ; pour la suivante ce sera $2 etc.
Lister les processus :
ps auxKILL un processus :
sudo kill -9 IDFaire un SSH via un proxy :
# Forward le trafic sur le port 8080 de mon ordinateur vers le port 80 de l'hote distant
ssh -L 8080:localhost:80 remote_host
Afficher les logs du boot précédent et ainsi voir à la toute fin, les logs de la dernière extinction du système.
journalctl -b -1Actualiser le /etc/fstab :
sudo mount -aCouper un affichage à partir d'un caractère :
cat monfichier.log | cut -d "|" -f 2Journalclt purge :
- Per days
journalctl --vacuum-time=2d- Per size
journalctl --vacuum-size=500M--> Après purge des fichiers de logs, pour libérer l'espace (uniquement si on supprime rsyslog ou daemon.log ):
systemctl restart rsyslogTaille dossier d'un niveau uniquement :
du -h --max-depth=1Supprimer un hostname des know_host ssh :
ssh-keygen -R hostnameLister les services actuellement fonctionnels :
sudo systemctl --type=service --state=running | awk '{print $1}'
UNIT
chrony.service
containerd.service
cron.service
dbus.service
docker.service
getty@tty1.service
google-cloud-ops-agent-diagnostics.service
google-cloud-ops-agent-fluent-bit.service
google-cloud-ops-agent-opentelemetry-collector.service
google-guest-agent.service
google-osconfig-agent.service
haveged.service
mariadb.service
nmbd.service
polkit.service
rsyslog.service
serial-getty@ttyS0.service
smbd.service
ssh.service
systemd-journald.service
systemd-logind.serviceCertificats :
Etablir une connexion ssl pour tester les certificats :
openssl s_client -connect host:port -CAfile chemin_vers_certificat_public_de_la_ca.pemDebug Deep :
Afficher les logs du noyeau linux :
dmesgKernel :
--> On va lister les vieux kernels présents sur le system. Puis on va les supprimer pour faire de l'espace dans /boot.
Kernel actuellement en cours d'execution :
uname -rX.X.X-26-amd64J'utilise donc le kernel : X.X.X-26-amd64
Liste des kernels présents dans le système (exépté le kernel actuellement utilisé) :
sudo dpkg --list 'linux-image*'|awk '{ if ($1=="ii") print $2}'|grep -v `uname -r`linux-image-X.X.X-18-amd64
linux-image-X.X.X-19-amd64
linux-image-X.X.X-20-amd64
linux-image-X.X.X-21-amd64
linux-image-X.X.X-22-amd64
linux-image-X.X.X-23-amd64Ici, nous allons pouvoir supprimer les versions X.X-18-amd64 à X.X-23-amd64 compris. Il faut toujours garder deux versions de kernels précédentes.
Pour supprimer les anciens kernels, je vais réaliser les commandes suivantes :
sudo apt purge linux-image-X.X.X-18-amd64
sudo apt purge linux-image-X.X.X-19-amd64
sudo apt purge linux-image-X.X.X-20-amd64
sudo apt purge linux-image-X.X.X-21-amd64
sudo apt purge linux-image-X.X.X-22-amd64
sudo apt purge linux-image-X.X.X-23-amd64
sudo apt purge linux-image-X.X.X-24-amd64Puis, je vais réaliser une purge des packets qui sont désormais obsolètes :
sudo apt autoremoveEnfin, on met à jour la liste des noyeaux grub :
sudo update-grubConclusion :
Mon /boot est passé de 427 Mo utilisés à 168 Mo.
TCPDUMP :
ARP:
sudo tcpdump -nni any vrrp--> Sur toutes les interfaces.
Récupérer un fichier perdu, supprimé :
Foremost permet de récupérer les fichiers supprimés. Cette récupération n'est pas parfaite car les données perdues peuvent être écrasés par une réécriture :
foremost -t all -i /dev/sda1Gestion du disque linux (LVM) :
Afficher les volumes physiques :
pvdisplayAfficher le groupe :
vgdisplayAfficher les volumes logiques :
lvdisplayAugmenter la taille d'un volume :
# Taille définie :
lvextend -L '+9G' /dev/vg0/lib
# Taille relative :
lvextend -l '+100%FREE' /dev/vg0/lib
Affecter la nouvelle taille :
xfs_growfs /var/libSupprimer un volume récalsitrant :
# Eteindre le volume.
lvchange -an -v /dev/vg0/lib
# Afficher les process qui utilisent le volume
lsof | grep /var/lib
# Si besoin de debug : Afficher les processus cachés qui utilisent le volume
grep -l /var/lib /proc/*/mountinfo
# --> Cette commande nous retounre des PID. Faire : ps -aux | grep <PID_ID> ; pour connaitre les service qui continuent d'utiliser le volume.
# Maintenant que nous avons éteinds tous les services qui posent problème, nous pouvons supprimer le volume.
lvremove -f vg0/lib
lvcreate -n lib -l 100%FREE vg0
mkfs.xfs /dev/vg0/libProcédure pour augmenter la SWAP :
free -h
swapoff /dev/vg0/swap
lvextend -L '+6G' /dev/vg0/swap
mkswap /dev/vg0/swap
swapon /dev/vg0/swap
free -hProcédure pour supprimer un volume "100%FREE" qui nous empéche forcément de créer un volume /home de 20 Go :
# Démonter /var/lib ; sauvegarder ; préparer au redémarrage
cp -pR /home /root/
cp -pR /var/lib /root/
umount /var/lib
cp -pR /root/lib/* /var/lib/
############################
############################
COMMENER LE /ETC/FSTAB (ligne lib) :
#/dev/vg0/lib /var/lib xfs rw,noatime,logbufs=8,logbsize=256k,inode64 1 2
############################
############################
Reboot
############################
############################
# Supprimer le volume
lvremove -f vg0/lib
##############################
# Créer les volumes qu'il faut
lvcreate -n home -L "20G" vg0
mkfs.xfs /dev/vg0/home
#...
lvcreate -n lib -l 100%FREE vg0
mkfs.xfs /dev/vg0/lib
##############################
# supprimer les données résiduelles avant remontage
rm -r /var/lib/*
rm -r /home/*
############################
DECOMMENTER LE /ETC/FSTAB !
+
AJOUTER LES MONTAGES neccessaires :
/dev/vg0/lib /var/lib xfs rw,noatime,logbufs=8,logbsize=256k,inode64 1 2
/dev/vg0/home /home xfs rw,noatime,logbufs=8,logbsize=256k,inode64 1 2
############################
mount -a
# VERIFIER
mount | grep /home
mount | grep /var/lib
# Réimporter les datas dans les volumes
cp -pR /root/lib/* /var/lib/
cp -pR /root/home/* /home/
# Reboot
reboot
# vérification
ls -lisa /var/lib
ls -lisa /home
# suppression des données dupliquées
rm /root/home -r
rm /root/lib -r
SSHD - Only sftp
Prérequits :
- home de l'user toto : /opt/toto
Configuration /etc/ssh/sshd_config :
Match User toto
ChrootDirectory /opt/toto
X11Forwarding no
AllowTcpForwarding no
AllowAgentForwarding no
PasswordAuthentication no
ForceCommand internal-sftp -d /%uCommandes pour rendre la chose fonctionelle :
mkdir /opt/toto/data
chown root:root /opt/toto
chown -R toto:toot /opt/toto/*
systemctl restard sshdTest :
sftp -i id_rsa toto@SERVEUR <<< 'put fichier.txt /data/'
# Test de perms
ssh -i id_rsa toto@SERVEUR
This service allows sftp connections only.
Connection to SERVEUR closed.
Gérer les ACL
Récupérer les informations d'un fichier :
stat launch_kee.sh
====================================================
Fichier : launch_kee.sh
Taille : 82 Blocs : 8 Blocs d'E/S : 4096 fichier
Périphérique : 254/1 Inœud : 4718858 Liens : 1
Accès : (0755/-rwxr-xr-x) UID : ( 0/ root) GID : ( 0/ root)
Accès : 2024-06-10 11:24:44.881570498 +0200
Modif. : 2024-06-10 11:24:33.865592246 +0200
Changt : 2024-06-10 11:24:41.201577761 +0200
Créé : 2024-06-10 11:24:29.949599980 +0200
Récupérer les ACL d'un fichier :
getfacl launch_kee.sh
=========================
# file: launch_kee.sh
# owner: root
# group: root
user::rwx
group::r-x
other::r-x
Ajouter les perms à un utilisateur :
sudo setfacl -m user:nehemie:rw- launch_kee.sh Constat :
getfacl launch_kee.sh
==============================
# file: launch_kee.sh
# owner: root
# group: root
user::rwx
user:nehemie:rw-
group::r-x
mask::rwx
other::r-x
Supprimer les perms à un utilisateur :
sudo setfacl -Rm user:nehemie:--- launch_kee.sh- - R : ACL Récurcif
Constat :
getfacl launch_kee.sh
====================================
# file: launch_kee.sh
# owner: root
# group: root
user::rwx
user:nehemie:---
group::r-x
mask::r-x
other::r-x
Réduire la valeur des ports privilégiés:
echo 80 | sudo tee /proc/sys/net/ipv4/ip_unprivileged_port_startLister les démons qui utilisent le dossier :
sudo lsof /var/lib/Convertir des timestamps milisencondes en date humaines :
# dans mon fichier tmp j'ai des lignes de timestamp en format ms
for line in $(cat /var/lib/db_backup/tmp); do date -ud @$(($line / 1000)); done;vmware-toolbox-cmd timesync enableInstaller un packet dans un conteneur debian bizzare :
apk add curl
apk add jq